Here is a list of reasons why some websites may not be crawled:
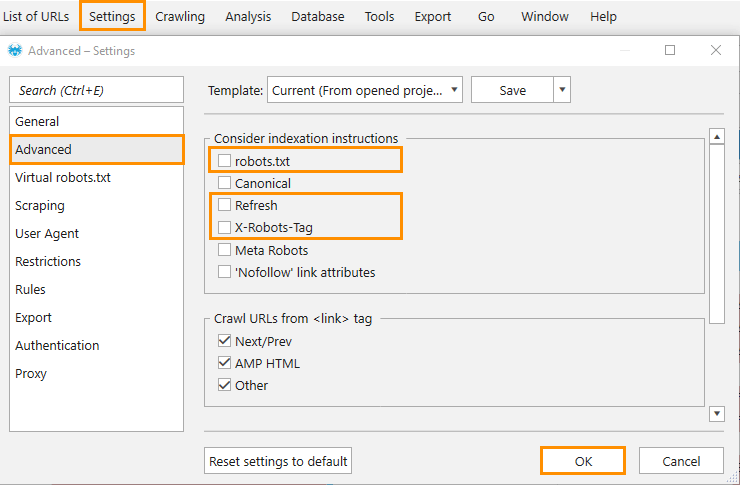
Website is disallowed from indexing in one or several ways – robots.txt, Meta Robots, X-Robots-Tag.
Solutions:- Turn off considering of these rules in the program settings on the ‘Advanced‘ tab.
- Allow indexing the website, otherwise it might have issues with organic traffic.
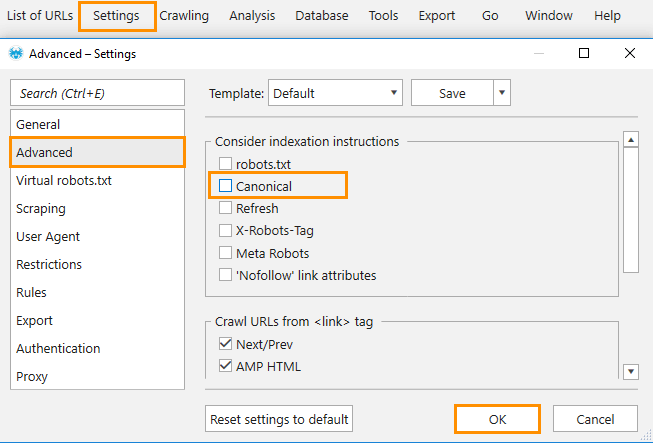
Canonical tag is set incorrectly. It often happens when switching to a new protocol.
Solutions:- Turn off considering of canonical instructions in the settings on the ‘Advanced’ tab.
- Set correct URL on a website in canonical tag.
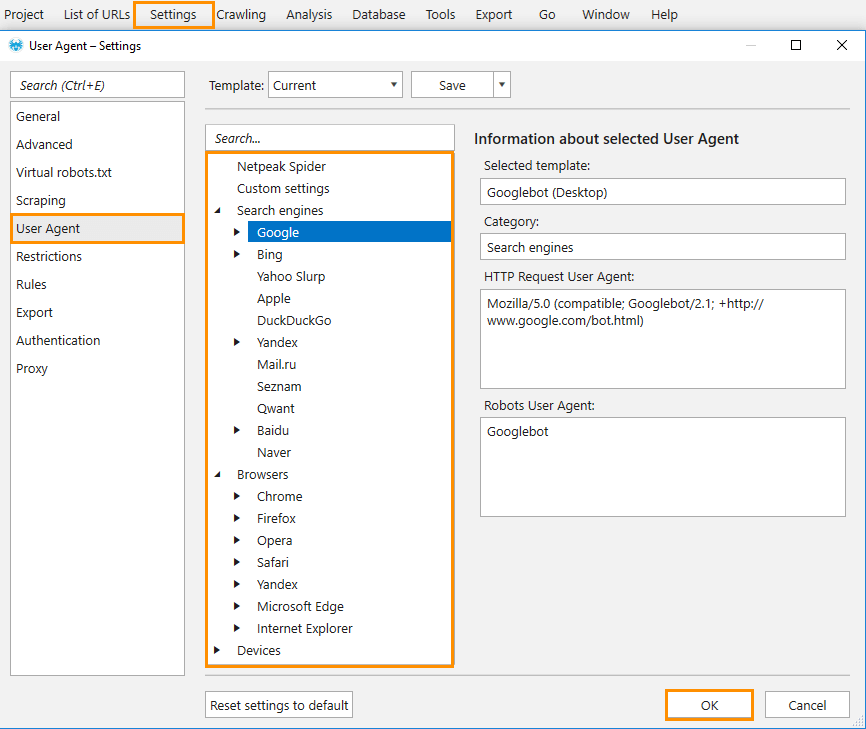
Access to your website is disallowed for a certain User Agent (for example, for Googlebot).
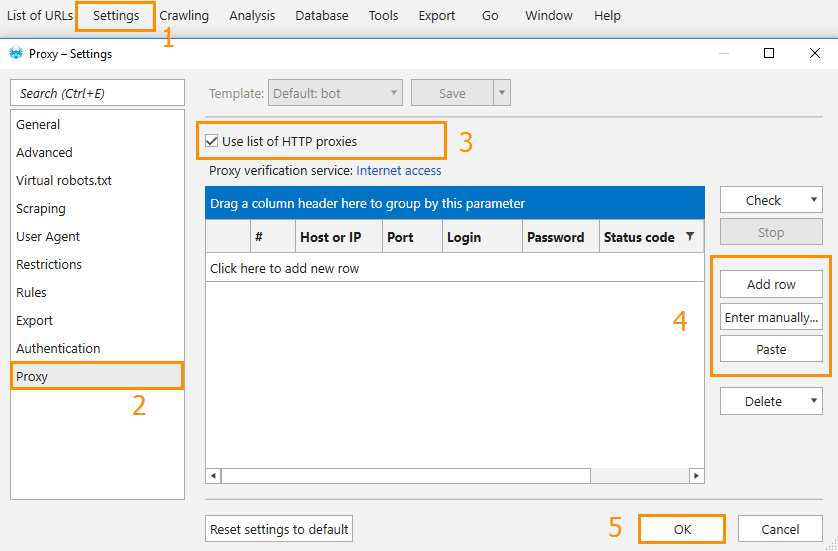
Solution: Change the current User Agent on the corresponding tab in settings.For some reason, your current IP-address has been banned on the crawled website.
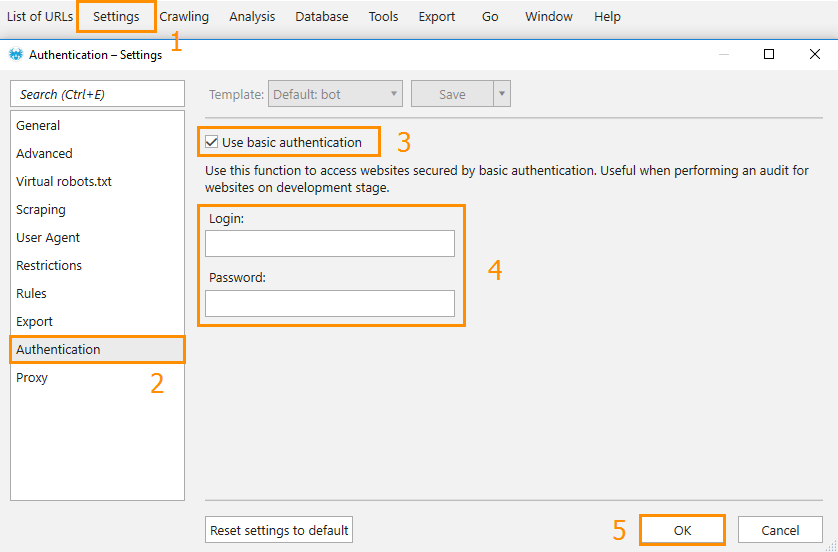
Solution: Using a proxy.Crawled website requires authentication.
Solution: Set authentication credentials (login/password) on the ‘Authentication’ tab in the crawling settings. This method works only for basic authentication which is included in the HTTP request and is often used when the website is on the development stage.The ‘SendFailure’ error may appear on websites with HTTPS connection if you use Netpeak Spider on Windows 7 SP1 or older because these versions of operating systems do not support the TLS 1.2 encryption.
Solutions:- Launch Netpeak Spider on a device with Windows 7 SP2 or later versions.
If you are the website owner, you can configure supporting older versions of encryption (TLS 1.0).
The ‘ConnectFailure’ error means that it is impossible to establish a connection with a server. It mostly happens when you crawl a website that uses HTTP-protocol. If you enter only a domain name in the ‘Initial URL’ field, the program will automatically add https-prefix to it, thus it will be impossible to establish a connection.
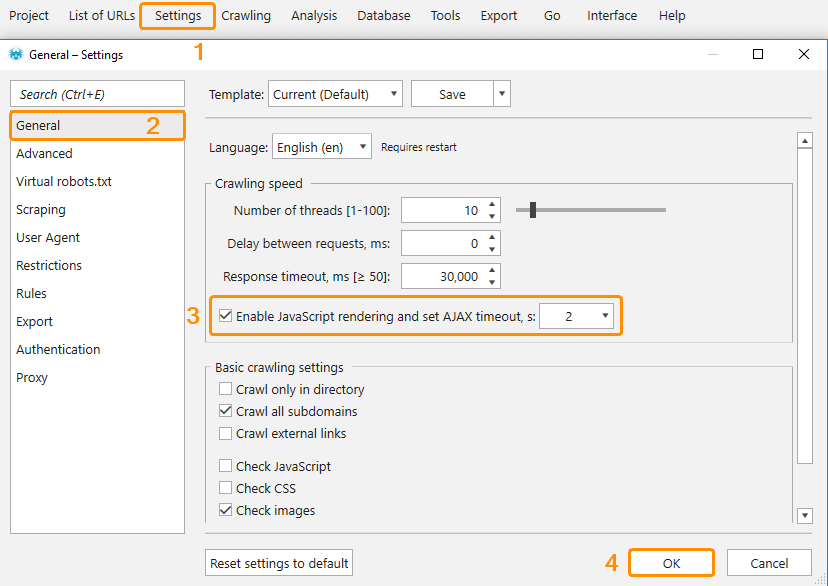
Solution: Enter a correct initial URL with the http-prefix.- A crawled website is developed with JavaScript. By default, Netpeak Spider crawls only static HTML code without JavaScript rendering.
Solution: Tick the option ‘Enable JavaScript rendering‘ on the ‘General‘ tab of the program settings. By necessity, change the Ajax Timeout (the delay in 2 seconds is set by default).
Pages of a crawled website return 5xx status code from the beginning of crawling or from a certain moment. This problem might mean that the server on which a website is located works incorrectly when receiving a lot of requests simultaneously, or it has protection from many simultaneous requests installed on it.
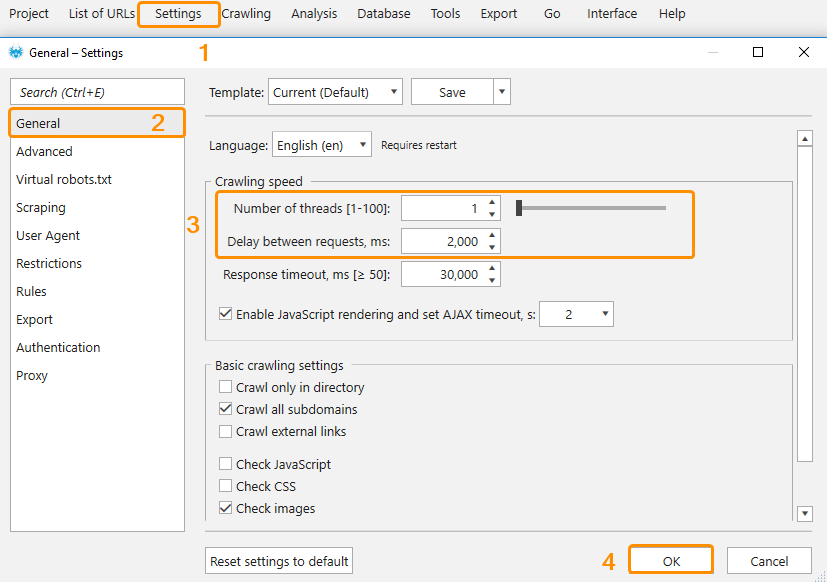
Solutions:Recrawl only pages with 5xx status code: decrease the number of threads on the ‘General’ tab in the settings, filter pages with 5xx status code and choose ‘Current table’ → ‘Rescan table’ in the context menu;
Recrawl an entire project: decrease the amount of threads in the same way and click ‘Restart’ to restart crawling.
We recommend using 2 threads for these websites. If the problem still appears, use only 1 thread and set 2000 ms delay between requests. The crawling will take more time, but these settings will help you to avoid excessive load on a server.
Note that 5-10 threads are not a high load: we advise providing a proper working of a server with this load, thus visitors can quickly and conveniently work with a website without long time waiting for a server response. If you often face these troubles, we recommend optimizing the server response time and/or choosing more appropriate hosting.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article