
В этом обновлении мы нацелились на то, чтобы вы ещё лучше понимали некоторые аспекты поисковой оптимизации и обучались SEO вместе с нами. Уделите немного времени и почитайте этот обзор, чтобы ознакомиться с новыми фишками и повысить свой навык владения Netpeak Spider :)
Инструмент просмотра исходного кода и HTTP-заголовков
Новый инструмент должен стать для вас настоящей неожиданностью!
Попробуйте просканировать любой URL и после того, как он появится в таблице с результатами, выберите нужную строчку и:
✔ вызовите контекстное меню нажатием правой кнопки мыши → пункт «Просмотреть исходный код и HTTP-заголовки»
...или...
✔ нажмите знаменитое сочетания клавиш → Ctrl+U
...или...
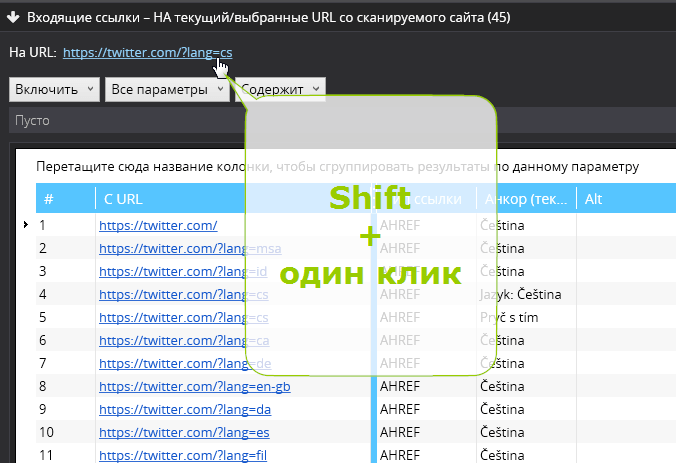
✔ зажмите Shift и кликните на любую ссылку 2 раза, если она в таблице, или 1 раз, если она вне таблицы.
Перед вами открывается инструмент, с помощью которого вы сможете просмотреть:
- общие данные, полученные при обращении к URL;
- данные о редиректах, если анализируемый URL перенаправляет в другое место;
- HTTP-заголовки ответа сервера;
- HTTP-заголовки запроса к серверу;
- список GET-параметров, если они присутствуют в URL;
- исходный код анализируемой страницы.
Область просмотра исходного кода страницы содержит в себе следующие приятные моменты:
✔ Просмотр различных типов файлов
В текущей версии вы сможете просматривать исходный код таких типов документов:
- HTML
- PlainText (например, TXT-файлы)
- JavaScript
- CSS (файлы стилей)
- XML
- GZIP → обратите внимание, что Netpeak Spider распакует архив и покажет содержимое, если его вежливо попросить :)
✔ Подсветка кода
Вам не придётся вчитываться в код, чтобы понять, где тег <title> или <meta name="description">, а где любимые ссылки → <a href="адрес">анкор</a>. Всё это легко можно будет найти благодаря подсветке кода.
Также знайте, что для каждого типа документа (которые перечислены в предыдущем пункте) используется своя индивидуальная подсветка. Таким образом вам будет легче работать как со стандартными HTML-файлами, так и с XML-картами сайтов, даже заархивированными с помощью gzip.
✔ Нумерация и автоперенос строк
Чтобы увидеть всю строку, не надо использовать горизонтальный скрол: одного вертикального скрола должно быть достаточно! А нумерация поможет не запутаться, где начинается, а где заканчивается строка.
✔ Поиск по коду с дополнительными функциями
Показывать исходный код, но не позволять по нему искать – деньги на ветер. Именно поэтому мы внедрили поисковую строку, которая по умолчанию включена. Однако, если вы её закрыли, то всегда сможете заново открыть, нажав на знакомую комбинацию клавиш Ctrl+F.
Здесь сконцентрирована большая часть фишек, которые мы советуем использовать в определённых ситуациях:
- выделите какую-нибудь часть текста и после этого нажмите Ctrl+F → выделенный текст автоматически вставится в поисковую строку и начнётся поиск;
- если для вас критично учитывать регистр букв, то можете включить соответствующий параметр в меню справа от поисковой строки → галочка «Учитывать регистр»;
- также есть возможность поиска только по целым словам: к примеру, если вам необходимо найти все вхождения слова «сайт», но при этом чтобы поиск не учитывал слова типа «сайта», «сайтов» и т.д. → галочка «Учитывать только целые слова»;
- для самых опытных – возможность использовать при поиске регулярные выражения: здесь необходимо понимать, какие задачи требуют внимания, а уже пределом для их решения может стать только ваша фантазия → галочка «Использовать регулярные выражения».
Обратите внимание, что на данные в новом инструменте влияют следующие настройки сканирования:
- User Agent → напомним, что в соответствующей вкладке в настройках сканирования вы можете выбирать User Agent из большого количества предустановленых шаблонов;
- Timeout → время ожидания ответа сервера, которое настраивается на вкладке «Ограничения» и по умолчанию равно 30 000 мс (или 30 секунд);
- максимальное количество редиректов → настраивается там же и по умолчанию равно 5;
- прокси → когда использование прокси включено, то в окне нового инструмента появляется соответствующая надпись сверху.
Признаемся, мы были просто вынуждены разработать этот инструмент, так как получали достаточно много вопросов от пользователей в стиле «А почему на сайте я вижу одно, а Netpeak Spider показывает другое?» – теперь некоторые подобные вопросы отпадут сами собой, потому что в каждой ситуации, где вы не уверены, почему возникла ошибка, вы всегда можете посмотреть, что именно видит Netpeak Spider и с чем его «заставляет» работать анализируемый сайт :)
Вот несколько кейсов, которые возникали у наших пользователей:
1) на сайте стоит какая-то защита → к примеру, на одном сайте стояла защита в виде проверки на файл cookie у пользователя: если проверка проходила успешно, то сайт загружался и можно было с ним работать; Netpeak Spider же (как и роботы поисковых систем) работает по умолчанию без поддержки cookie – грубо говоря, начиная каждую сессию с чистого листа – потому мы не видели контент анализируемой страницы и показывали ошибку;
2) на странице отсутствует часть стандартных HTML-тегов → в этом случае пользователь видел верхнюю часть страницы, которая успела загрузиться в браузере и полагал, что со страницей всё в порядке, однако Netpeak Spider не видел закрывающиеся теги </body> и </html> из-за того, что сервер их попросту не возвращал;
3) под разными User Agent отдаётся разный контент → из-за этого пользователь видел «свой» сайт, а мы – совершенно другой;
4) для разных IP отдаётся разный контент → доходили случаи и до блокировки доступа к сайту, и до редиректов, если ваш IP относится к определённой стране: именно для этого мы отдельно в программе показываем, что вы работаете через прокси.
Во всех этих кейсах новый инструмент поможет быстрее разобраться, чем отличается ваше посещение сайта в браузере от краулинга с помощью Netpeak Spider, и что именно мешает программе получить доступ к ресурсу.
В итоге больше нет необходимости постоянно переключаться в панель разработчика в браузере или пользоваться сторонними онлайн-сервисами → почти любую задачу, связанную с HTTP-заголовками или исходным кодом, можно решить прямо в интерфейсе Netpeak Spider (как говорится, не отходя от кассы)!
5 новых ошибок
Мы очень любим находить ошибочки на ваших сайтах, но особенно мы радуемся, когда вы находите ошибки на них раньше, чем это делают поисковые системы. Мы обещали расширять список ошибок, потому в этом обновлении мы сдерживаем обещание и представляем вашему вниманию 5 новых ошибок:
1. Неправильная структура HTML-документа
Критичность ошибки: высокая. Выше мы немного затронули эту тему, а теперь системно подходим к вопросу определения того, что HTML-документ не содержит обязательные теги:
А если ваши страницы не содержат эти стандартные теги, то поисковые системы вряд ли вас похвалят за это… скорее наоборот :(
2. Ссылки с неправильным форматом URL
Критичность ошибки: высокая. У нас во внутренних таблицах типа «Входящие ссылки» / «Исходящие ссылки» уже достаточно давно было определение ссылок с неправильным форматом → это ссылки, которые не соответствуют стандартному максированию URL:
схема:[//[логин:пароль@]хост[:порт]][/]путь[?параметры][#якорь]
Вот несколько примеров такой ошибки:
- <a href="http:// example.com/">Ссылка с пробелом между протоколом и доменом</a>
- <a href="https://#">Ссылка без хоста</a>
Теперь мы определяем, что страница содержит подобные ссылки, и сразу же бьём тревогу. Чтобы увидеть полный отчёт по таким ссылкам, отфильтруйте страницы по данной ошибке, нажмите кнопку «Сводка по текущей таблице», выберите пункт «Исходящие ссылки» и настройте соответствующий фильтр (Включить → URL с ошибкой → Неправильный формат URL).
3. Внешние 4xx-5xx ошибки
Критичность ошибки: высокая. Когда вы включаете анализ внешних ссылок (галочка «Сканировать внешние ссылки» на вкладке «Основные» в настройках сканирования), то при обнаружении в них ошибок с 4xx или 5xx кодом ответа сервера, они будут собраны именно в этом фильтре.
Старайтесь избегать подобных ссылок, чтобы пользователи сайта были довольны, а поисковые системы считали ваш сайт уютным местечком.
4. Редирект на внешний сайт
Критичность ошибки: средняя. Если Netpeak Spider обнаружил, что целью внутреннего перенаправления является другой сайт, то именно в этом фильтре будут собраны все страницы-источники таких редиректов.
Обратите внимание на настройку «Сканировать все поддомены» или «Учитывать поддомены» (в зависимости от режима сканирования) – она позволяет управлять нашим краулером с точки зрения определения, являются ли ссылки на поддомены данного сайта внутренними или внешними. Таким образом, если вы отключите эту галочку, то будьте готовы увидеть ошибку «Редирект на внешний сайт» в случае, если конечным URL редиректа был именно поддомен.
5. URL не содержит протокол https
Критичность ошибки: низкая. Сейчас достаточно модно переходить на более защищённый https-протокол, потому что поисковые системы учитывают это как отдельный фактор ранжирования документов. Если это так важно, а переход на https не является чем-то сверхсложным (особенно, если у вас 1 домен без многочисленных поддоменов), то мы решили показать это как ошибку с низким приоритетом в стиле «не забудьте об этом».
Зарегистрируйтесь, если вы ещё не с нами
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд!
Коротко о главном
Коллеги, в обновлении Netpeak Spider 2.1.1 мы реализовали новый инструмент, позволяющий внутри программы просматривать исходный код страниц, HTTP-заголовки и дополнительную информацию об URL, а также внедрили определение 5 новых ошибок:
- Неправильная структура HTML-документа
- Ссылки с неправильным форматом URL
- Внешние 4xx-5xx ошибки
- Редирект на внешний сайт
- URL не содержит протокол https
Для нас эта версия является своеобразным экватором на пути к Netpeak Spider 2.1.3 – очень важному событию в жизни нашего SEO-краулера. Мы уже разрабатываем новые фишки и скоро будем готовы снова вас порадовать!
Понравилось обновление? Давайте лично обсудим все детали и преимущества Netpeak Spider

Статья помогла?
Отлично!
Спасибо за ваш отзыв
Извините, что не удалось помочь!
Спасибо за ваш отзыв
Комментарий отправлен
Мы ценим вашу помощь и постараемся исправить статью