
Подробнее читайте в посте про обновление «Netpeak Spider 3.2: рендеринг JavaScript и экспресс-аудит в PDF».
Всем привет, сегодня я хочу рассказать об обновлении нашего краулера Netpeak Spider 3.2. Этот релиз я сам ждал с нетерпением: PDF-отчёт, тонны полезной информации по ошибкам, добавлена поддержка работы с сайтами, которые используют JavaScript, и многое другое.
1. Работа с сайтами, которые используют JavaScript
Перейти к этому разделу на Youtube
Использование JavaScript на сайтах перестало быть редкостью, всё больше сайтов уже разрабатываются с использованием скриптов или планируют мигрировать на версию с ними. К сожалению, нововведения хоть и дают больше возможностей в реализации наших задач, но также зачастую провоцируют множество проблем, потому мы рады сказать, что теперь Netpeak Spider сможет помочь вам в их решении.
Всё, что нужно для активации функции рендеринга JS, это поставить галочку в настройках напротив пункта «Включить рендеринг JavaScript и установить AJAX timeout, c:».
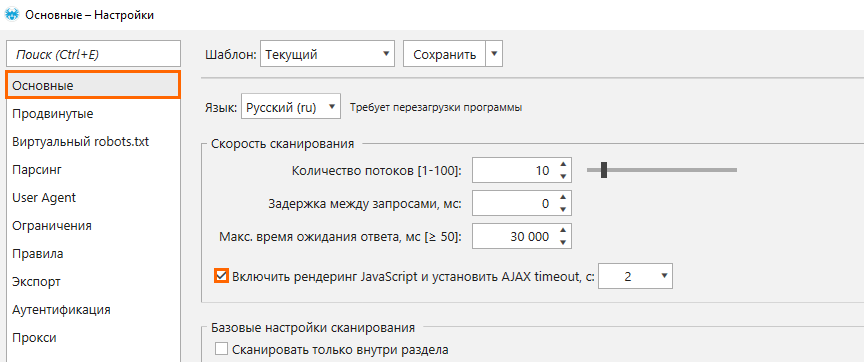
Мы установили по умолчанию 2 секунды на выполнение скриптов, так как в большинстве случаев этого достаточно, но если на вашем сайте они обрабатываются дольше, тогда дайте больше времени на этот процесс. Не забывайте: если в краулере можно установить необходимое время на ожидание, то пользователь не всегда такой послушный. Потому, если скрипты отрабатывают слишком долго, нужно задуматься над их оптимизацией.
Программа будет использовать JS-рендеринг только для 200 ОК HTML-страниц, чтобы не тратить ресурсы на страницы, для сканирования которых его не нужно использовать. Использование рендеринга значительно влияет на скорость сканирования сайта, потому что дополнительно происходит запрос в Chromium для получения HTML-кода, загрузка JS и CSS-файлов и само выполнение JavaScript. Потому не включайте его всегда, ведь всё ещё огромное количество сайтов, где не нужен рендеринг JS.
Хочу заметить несколько вещей, которые полезно знать:
- Во время рендеринга программа блокирует запросы к аналитическим сервисам (Google Analytics, Яндекс.Метрика и т.д.), чтобы не искажать аналитику сайта.
- Cookies будут использоваться независимо от того, включена ли эта настройка на вкладке «Продвинутые».
- Содержимое iframe и изображения на сайте не будут загружаться во время сканирования.
- Есть ограничение по количеству потоков: 25. Если вы выставили в настройках 100 потоков, наш краулер будет одновременно сканировать 100 документов обычным способом, однако рендеринг будет работать только с 25 страницами.
Потому, как говорил Морфеус в Матрице, выбирайте с умом, нужна ли вам эта функция для следующего сканирования.
2. Технический SEO-аудит (PDF)
Перейти к этому разделу на Youtube
Мы создали PDF-отчёт, который поможет SEO-специалистам быстро понять текущее состояние оптимизации просканированного сайта без выполнения дополнительных манипуляций. Мы собрали в этом отчёте ключевую информацию для выполнения аудита сайта, а если вы дополните её собственными выводами и рекомендациями, тогда его вполне можно отправлять вашим клиентам или коллегам как настоящее ТЗ.
Перед тем, как перейти к рассмотрению самого отчёта, хочу добавить, что если вы занимаетесь продажей услуг продвижения сайтов, этот отчёт поможет вам собрать краткую сводку о текущем состоянии сайта, после чего вы сможете намного быстрее оценить проект и обсудить дальнейшие работы с клиентом.
Если вы ещё не видели наш суперкрасивый PDF-отчёт, тогда у меня для вас две новости:
- Вы многое пропустили.
- Не стоит переживать, мы с вами вместе сейчас пройдём по нему, чтобы детальнее рассмотреть всю информацию, которая содержится в отчёте.
2.1. Заглавная страница + содержание
На первом листе размещается изображение первого экрана начальной страницы, если программа работала в режиме сканирования сайта, или специальная картинка, если вы сканировали список URL без начальной страницы. Затем вы увидите содержание с навигационными ссылками, чтобы вы могли быстро перемещаться по разделам в файле.
2.2. Сводка
На втором листе вы увидите прокаченную версию вкладки «Сводка» из боковой панели программы. Здесь отображаются такие данные:
- Режим сканирования → проверка сайта или проверка списка URL.
- Начальный URL сканирования. Если был просканирован список URL, то здесь отобразится первый URL из списка.
- Количество параметров, которые были выбраны во время генерации отчёта.
- Количество и типы URL, по которым построен текущий отчёт.
- Количество URL с важными ошибками (высокой и средней критичности).
- Самые распространённые ошибки на сайте.
- Тип контента для внешних и внутренних страниц → мы разделяем эти страницы на разные диаграммы и дополнительно выделяем их разными цветами, чтобы легче воспринималась эта информация.
- Основные хосты → эта таблица будет полезна для понимания количества страниц на различных поддоменах вашего сайта. Также, например, проверяя список страниц, можно быстро понять, сколько из них относятся к одинаковым хостам.
2.3. Структура URL
Эта таблица представляет собой краткую выжимку из полного отчёта «Структура сайта», показывая самые популярные сегменты URL, количество страниц, которые к ним относятся, и процентное соотношение таких страниц к общему количеству просканированных.
2.4. Коды ответов сервера
Этот раздел показывает все коды ответа, которые программа получила в ходе сканирования, разделяя их для внешних и внутренних страниц на разные графики. Больше всего внимания советую уделить редиректам и четырёхсотым и пятисотым кодам — лучше всего сделать так, чтобы их в отчётах совсем не было.
2.5 Сканирование и индексация контента
На следующем листе мы собрали информацию о факторах, которые влияют на сканирование и индексацию контента на вашем сайте. Неиндексируемые документы зачастую не приносят трафик из поисковых систем или могут расходовать драгоценный краулинговый бюджет. Хочу заметить, что эта информация относится только к внутренним URL. Зелёным цветом отмечены инструкции, которые ничего не ограничивают, жёлтым — влияющие на переход робота по ссылкам и результаты в выдаче поисковых систем, красным — влияющие на наличие документа в индексе, а чёрным — остальные найденные инструкции. Кстати, удобная таблица о содержимом тегов canonical, например, позволяет быстро понять сколько страниц у вас каноникализированны.
2.6. Глубина и вложенность URL
В данном разделе показано распределение количества страниц по глубине (количество кликов от начальной страницы) и вложенности URL (количество сегментов в адресе документа). Обратите внимание: в отчёте анализируются только внутренние индексируемые HTML-страницы. Если вы видите много страниц с глубиной или вложенностью 4 и больше, это значит, что такие страницы могут хуже индексироваться, или же слишком длинный адрес может быть непонятен посетителям сайта, что в результате не сыграет вам на руку.
2.7. Скорость загрузки
Мы сделали максимально подробную разбивку страниц по типам, чтобы вы могли посмотреть время ответа сервера для каждого из них отдельно. Что ещё интересно: мы показываем минимальные, максимальные значения и медианы отдельно для внутренних, внешних HTML-страниц, изображений и ресурсов. Мы постарались максимально понятно и удобно сделать эти графики, ведь скорость загрузки является одним из важных факторов ранжирования, потому требует особого внимания в ходе оптимизации. Да и честно говоря, это влияет не только на SEO: если я захочу купить кроссовки, а сайт будет долго отвечать, я пойду к другому продавцу. Потому давайте делать интернет быстрее и лучше вместе ;)
2.8. Протоколы HTTP/HTTPS
Здесь показано распределение страниц, которые используют защищённый (HTTPS) и незащищённый (HTTP) протоколы. Если на сайте с HTTPS-протоколом есть HTML-страницы, изображения или ресурсы с HTTP-протоколом, это может привести к ошибке «Смешанное содержимое». В этом случае пользователи могут увидеть в браузере соответствующее предупреждение, а поисковые системы будут считать сайт небезопасным. Чтобы избежать этого, постарайтесь убрать все HTTP-ссылки с вашего сайта, ну и камон, 21 век за окном, можно использовать даже бесплатный SSL. Если вы ещё не переехали, советую начать процесс как можно быстрее.
2.9. Оптимизация контента
Если у вас на сайте есть индексируемые страницы с дублями или же слишком короткими / длинными title, description и H1 — сейчас отличное время исправить эти ошибки, которые могли замедлять вас на пути к вершине выдачи. Дополнительно мы показываем графики по размеру контента на страницах и размеру изображений, которые мы проанализировали в ходе сканирования. Есть крутая фича для тех, кто любит всё настраивать под себя: на вкладке «Ограничения» в настройках сканирования можно задать область значений для построения этого отчёта, например, какой title или h1 считать длинным или коротким. Чтобы это сделать, достаточно перейти на вкладку «Ограничения» в настройках сканирования и задать нужные лимиты.

2.10. Ошибки
Это мой любимый раздел, потому что отлично показывает, насколько всё плохо. Обычно люди думают, что у них на сайте всё куда лучше, чем на самом деле — проверено на нескольких сотнях участников конференции 8Р летом 2018 года. Предлагаю провести подобный эксперимент среди тех, кто посмотрит это видео:
- Сделайте предположение, сколько ошибок (высокой и средней критичности) Netpeak Spider найдёт на вашем сайте .
- Просканируйте сайт и узнайте, сколько их действительно найдётся.
- Напишите в комментариях к этому видео, большой ли разброс между предположением и реальностью.
Вернёмся к отчёту. Мы показываем:
- Распределение критичности ошибок по страницам сайта, то есть сколько страниц содержат ошибки разных степеней критичности;
- Топ важных ошибок по количеству страниц, на которых они найдены, потому что если пофиксить 10 000 страниц с редиректами, это может дать больше эффекта, чем исправление пяти битых ссылок;
- Таблицы, которые показывают найденные ошибки, ссылки на документацию по каждой из них, пример страницы, на которой она была найдена и количество таких страниц.
Мы сделали именно так, чтобы не создавать PDF-отчёт с перечнем всех URL, на которых найдена ошибка. Эта информация занимает слишком много места, а с ней всё равно удобнее работать в табличном редакторе.
Завершает этот раздел таблица с ошибками, которые не были найдены на сайте. Потому желаю вам большой последней таблицы в этом разделе ;)
2.11. Термины и настройки
На последних листах мы кратко описали термины, которые используем, а также показали параметры и настройки сканирования, которые использовались при создании данного экспресс-аудита. Здесь вы увидите и параметры, которые не были использованы в ходе краулинга.
Последний лист отчёта — это небольшая сводка информации о нашей компании и полезные ссылки. Не забудьте покликать по ним, нам будет очень приятно, если вы будете знать больше о нас и наших программах.
Ставьте лайк этому видео, если PDF-отчёт огонь, а если есть пожелания по улучшению, welcome в комментарии — всё учтём и постараемся реализовать ;)
3. Расширенное описание ошибок
Перейти к этому разделу на Youtube
Как я уже говорил ранее, большинство людей думают, что их сайт лучше, чем он есть на самом деле. Когда вы видите огромное количество ошибок, которые нашёл краулер, в начале вы хотите разобраться, а что эти ошибки означают, чем могут навредить, и главное — как их исправить? Мы получили бесчисленное множество обращений в поддержку, где нас просили объяснить значение разных ошибок, почему это считается ошибкой и так далее. Мы выпустили обновление, в котором для каждой ошибки в программе прописали ответы на эти вопросы и предоставили дополнительные ссылки на информацию, которая поможет разобраться даже новичку.
Вся информация по ошибкам находится на панели «Информация» в нижней части программы: чтобы её увидеть, достаточно кликнуть на ошибку, которая вас интересует. Кстати, дополнительно мы собрали всю эту информацию в центре поддержки на нашем сайте, чтобы вы могли прочесть её даже на телефоне, планшете или (вдруг) распечатать.
Можно даже экспортировать специальный отчёт, который будет содержать описание всех ошибок, которые были найдены в ходе сканирования сайта. Чтобы экспортировать этот отчёт, перейдите в меню «Экспорт» → «Отчёты по ошибкам» → «Сводка по ошибкам + описания». Если вы экспортируете пакетные выгрузки, например, «Набор основных отчётов», «Все ошибки» или «Все доступные отчёты (основные + XL)», такой отчёт сразу будет туда добавлен, чтобы упростить вам процесс передачи задания вашим коллегам или подрядчикам.
4. Остальные изменения
Перейти к этому разделу на Youtube
Предлагаю перейти к менее заметным изменениям в краулере:
- Мы поменяли степень критичности для ряда ошибок:
- Из средней критичности в высокую перешли:
- Дубликаты H1. Потому что использование одинаковых заголовков первого уровня на разных страницах может привести к так называемой каннибализации ключевых слов, когда разные страницы будут бороться за показы по одинаковым ключам, что приведёт в замешательство поисковые системы, ведь они не будут понимать, какая из страниц более релевантна.
- Цепочка канонических URL. Из-за того, что в такой ситуации канонический URL может быть проигнорирован поисковым роботом, это может привести к появлению дубликатов на сайте и потере трафика, как следствие.
- 5xx ошибки: Server Error. Такие страницы могут свидетельствовать о множестве различных проблем у вас на сервере, а пользователи могут посчитать сайт некачественным. Иногда сайт может отвечать пятисотым кодом из-за проведения технических работ, потому, если в ходе сканирования на вашем сайте были найдены такие страницы, лучше перепроверить их.
- Неправильный формат AMP HTML. Если вы уже потратили свои силы и ресурсы на создание AMP-версии страниц сайта, то наверняка не хотите, чтобы на ультрасовременных страницах появились какие-либо проблемы. Потому мы стараемся обратить максимум внимания на эту ошибку, разместив её в группу высокой критичности.
- А к ошибкам низкой критичности теперь относятся:
- Неправильный формат тега Base теперь является ошибкой низкой критичности, так как он используется достаточно редко, а при ошибке в этом теге Google не будет его учитывать.
- Несколько заголовков H1 и Макс.длина URL — потому что даже представитель Google Джон Мюллер сказал, что можно не переживать в этих случаях. Несколько H1 — это норма для HTML5 и множества CMS, а трудностей в обработке длинных URL нет, но они должны быть понятны пользователю (ЧПУ). Хотя посоветовал не использовать длину URL в 2 000 символов или больше.
- Из средней критичности в высокую перешли:
- У нескольких ошибок и параметров поменяли названия, чтобы вы легче понимали их суть:
- Битые ссылки стали битыми страницами, чтобы не запутывать вас, так как после клика покажутся именно битые страницы, а ссылки на них можно посмотреть в отдельном интерфейсе, нажав кнопку «Отчёт об ошибке», или даже выгрузить через меню «Экспорт».
- Дубликаты Canonical URL → Одинаковые канонические URL. Мы переименовали эту ошибку, чтобы уменьшить негативное восприятие этой ошибки, ведь это далеко не всегда что-то плохое, как, например, дубликаты title или H1.
- Изменили логику в определении ошибок и параметров:
- Для ошибки «Неправильный формат тега Base»: раньше относительный URL в этом теге считался ошибкой. Теперь ошибка определяется, если в атрибуте href указан URL с неправильным форматом.
- Теперь в параметре «Канонический URL» по умолчанию учитывается только абсолютный URL, как и требует Google. Потому, если на странице указан относительный адрес, мы в таблице будет записывать значение (NULL). Хочу сразу заметить: мы понимаем, что многие могут всё ещё использовать относительный URL в canonical, так как это распространённая практика, потому в настройках сканирования на вкладке «Продвинутые» мы добавили чек-бокс «Сканировать относительные канонические URL». Если возле этого пункта будет отмечена галочка, программа будет автоматически преобразовывать найденный относительный URL в абсолютный и заносить его в таблицу. У нас уже есть план, как сделать работу с этим элементом удобнее, потому в следующих обновлениях программы можно ожидать добавление новых ошибок, которые касаются canonical.
- Мы изменили сортировку в списке ошибок: теперь выше будут находиться самые распространённые и важные ошибки.
- Изменена логика определения внутренних адресов для списка URL. Чтобы определить, является ли ссылка внешней или внутренней, Netpeak Spider учитывает «Начальный URL»: если домен совпадает, ссылка считается внутренней, если нет — внешней. Раньше при сканировании списка URL (и при отсутствии начального) все ссылки считались внешними. Теперь же они сравниваются друг с другом: если все хосты адресов принадлежат одному домену, URL пойдут в отчёт о внутренних ссылках; если хотя бы один URL относится к другому домену, все адреса будут считаться внешними. Это сделано для более понятного отображения данных в отчётах.
- Вместе с появлением функции выполнения JavaScript, мы были вынуждены отказаться от поддержки операционных систем Windows ниже версии 7 SP1, так как более старые версии не поддерживают фреймворк .NET версии 4.5.2, который мы использовали для улучшения нашего продукта. Если у вас компьютер использует эти старые версии Windows, советую вам обновиться, ведь это касается не только Netpeak Spider, но и множества других программ, которые используют новые технологии для реализации самых крутых инструментов.
5. Подведём итоги
Перейти к этому разделу на Youtube
В обновлении Netpeak Spider 3.2 мы:
- Реализовали возможность рендеринга JavaScript на сайте, чтобы вы могли работать с этим быстроразвивающимся направлением.
- Добавили красивый и самое главное информативный PDF-отчёт с техническим SEO-аудитом, который будет полезен и SEO-специалистам, и проджект-менеджерам, и даже отделу продаж для быстрой оценки сайта.
- Написали множество контента по ошибкам, которые находит краулер Netpeak Spider на сайтах. Теперь по любой из ошибок вы можете посмотреть:
- Что является причиной появления ошибки?
- Чем она грозит вашему сайту?
- Как её устранить?
- Полезные материалы, которые помогут ещё лучше разобраться с каждой из ошибок.
- Реализовали более 50 других улучшений, чтобы вам было ещё удобнее использовать Netpeak Spider. Кстати, очень много улучшений мы делаем на основе идей наших пользователей, потому что вы являетесь реальными тестировщиками наших продуктов на просторах интернета, где можно встретить огромное количество разных ситуаций, которые точно не придумаешь из головы.
Всем спасибо за внимание, мне очень приятно, что вы досмотрели до конца это видео! Если вам понравилось обновление Netpeak Spider 3.2, жмите лайк под видео, а если есть ещё пожелания по улучшению программ или моих видео, пишите в комментарии, мне всегда интересно читать ваши сообщения ;) Люблю в конце вам что-то говорить приятное, потому сегодня хочу пожелать роста позиций по важным ключам и минимального количества багов, па-па ;)
Понравилось обновление? Давайте лично обсудим все детали и преимущества Netpeak Spider

Статья помогла?
Отлично!
Спасибо за ваш отзыв
Извините, что не удалось помочь!
Спасибо за ваш отзыв
Комментарий отправлен
Мы ценим вашу помощь и постараемся исправить статью