- Розгляд інструкцій сканування та індексації.
- Сканування посилань із тегу посилання.
- Автоматична зупинка сканування.
- Додаткові налаштування.
Просунуті налаштування можна знайти в розділі «Налаштування → Просунуті». Вони використовуються для налаштування процесу сканування, зокрема:
- слідувати чи ні інструкціям індексування;
- розглядати чи ні посилання з тегу ;
- автоматично припинити сканування.
1. Розгляд інструкцій щодо сканування та індексування
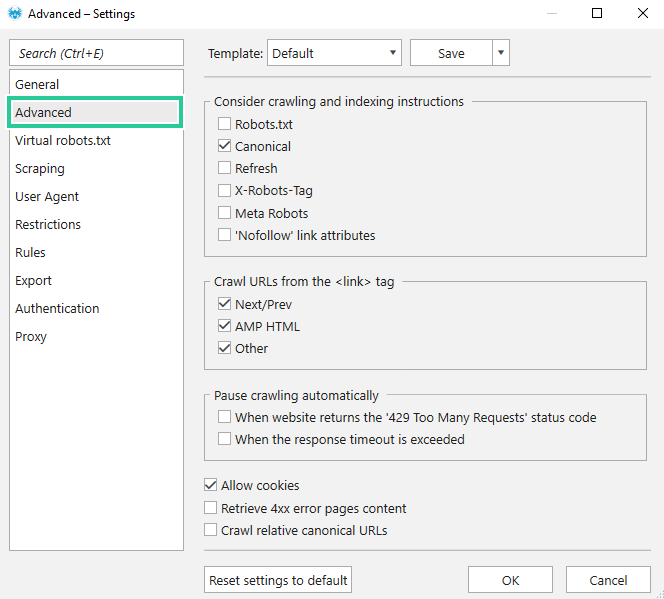
Це перший і найважливіший розділ додаткових налаштувань. Він включає такі конфігурації, як:
1.1. Robots.txt → поставте прапорець, щоб враховувати директиви з файлу robots.txt для обраного агента користувача: Дозволити/Заборонити облікові записи для додавання певної сторінки до таблиці результатів.
Зверніть увагу, що браузер Google Chrome використовується як агент користувача за замовчуванням для запитів HTTP, але для віртуального robots.txt використовується бот Netpeak Spider. Причина в тому, що Google Chrome User Agent не враховує директиви robots.txt, а нам потрібно перевірити, як вони працюють для різних ботів.
Ви можете протестувати директиви з файлу robots.txt, коли вебсайт знаходиться на стадії розробки, використовуючи функцію «Віртуальний robots.txt» у Netpeak Spider. Це дозволяє тестувати нові або оновлені директиви в robots.txt без зміни реального файлу.
1.2. Canonical → поставте прапорець, щоб враховувати канонічні вказівки в тегу у розділі документа або ‘Link: rel=”canonical”‘ у заголовку відповіді HTTP та вважати посилання з них єдиними вихідними посиланнями зі сторінки. Параметр встановлено за замовчуванням.
1.3. Оновити → поставте прапорець, щоб враховувати інструкції щодо оновлення в заголовках відповіді HTTP або тег у розділі документа та вважати посилання з цієї директиви єдиними вихідними посиланнями зі сторінки.
1.4. X-Robots-Tag → поставте прапорець, щоб враховувати інструкції X-Robots-Tag у заголовку відповіді HTTP для обраного агента користувача:
- Облікові записи Follow/Nofollow для розгляду посилань із певної сторінки;
- Облікові записи Index/Noindex для додавання певної сторінки до таблиці результатів.
1.5. Атрибути посилань «Nofollow» → поставте галочку, щоб не переходити за посиланнями з атрибутом «nofollow», наприклад https://example.com/” rel=”nofollow”>Приклад.
Зауважте, що коли Netpeak Spider виконує вказівки індексування, заборонені сторінки не скануватимуться, а додаватимуться до таблиці «Пропущені URL-адреси». Однак, незалежно від налаштувань і параметрів, Netpeak Spider завжди розділяє результати на сумісні, несумісні та не HTML-сторінки.
Майте на увазі, що роботи пошукових систем в будь-якому випадку враховують канонічні інструкції, директиви в robots.txt і Meta Robots, тому у випадку їх відсутності або неправильної конфігурації сайт може мати проблеми з індексацією.
2. Сканування посилань із тегу посилання tag
Щоб налаштувати сканування посилань із тегу tag, використовуйте такі параметри:
- Наступний/Попередній → поставте прапорець, щоб переходити за посиланнями і у розділі документа.
- AMP HTML → поставте прапорець, щоб переходити за посиланнями з тегів block.
- Інше → поставте прапорець, щоб додати всі URL-адреси з інших тегів у розділі документа до таблиці результатів. Зауважте, що цей параметр ігнорує директиви rel=”stylesheet” (CSS), rel=”next/prev”, і rel=”amphtml” оскільки вони охоплюються іншими налаштуваннями.
3. Автоматична зупинка сканування
У розділі «Автоматично призупинити сканування» ви можете налаштувати автоматичне припинення сканування у випадках:
- Коли вебсайт повертає код статусу «429 Too Many Requests» → сканування буде призупинено, коли сервер повертає код статусу 429.
- Коли час очікування відповіді перевищено → сканування буде призупинено, якщо час очікування відповіді перевищено. За замовчуванням це 30 секунд, але ви можете змінити цей параметр на вкладці налаштувань сканування «Загальні».
Ви можете будь-коли відновити сканування.
4. Додаткові налаштування
Ця вкладка містить такі налаштування, як:
- Дозволити файли cookie → поставте прапорець, якщо аналізований вебсайт закритий для всіх запитів без файлу cookie. Також усі запити будуть відстежуватися протягом одного сеансу. Інакше кожен новий запит створюватиме новий сеанс. За замовчуванням цей параметр увімкнено.
- Отримати вміст сторінок із помилками 4xx → поставте прапорець, щоб отримати всі вибрані параметри сторінок, які повертають код стану 4xx.
- Сканувати пов’язані канонічні URL-адреси → поставте прапорець, щоб увімкнути сканування пов’язаних канонічних URL-адрес у тегу у розділі документа або в заголовку відповіді HTTP «Посилання: rel=”canonical». У цьому випадку знайдені URL-адреси будуть додані в таблицю результатів.
Щоб скинути налаштування на поточній вкладці налаштувань, скористайтеся кнопкою «Відновити налаштування за замовчуванням» або встановіть шаблон «За замовчуванням», щоб скинути налаштування на всіх вкладках.
Ця стаття була корисною?
Чудово!
Дякуємо за відгук
Даруйте, що не вдалося допомогти вам
Дякуємо за відгук
Відгук надіслано
Дякуємо за допомогу! Ми докладемо всіх зусиль, щоби виправити статтю