1.1. General settings
1.2. Advanced settings
1.3. User Agent settings
2. Crawling:
2.1. Crawling process
2.2. Changes in settings during crawling
2.3. Pause and resume crawling
2.4. Data analysis
3. Saving the project and exporting the results
Netpeak Spider provides a wide range of custom settings and templates. In this article, you’ll learn how to start crawling quickly and how to configure Netpeak Spider.
1. Default settings
The default settings template is suitable for general analysis of the site status and standard SEO tasks. It affects such settings tabs:
- General
- Advanced
- Virtual robots.txt
- Scraping
- User Agent
- Restrictions
- Rules
You can always return to default template by choosing it from a template dropdown menu in the upper settings window and it will be applied to the program settings tabs listed above.
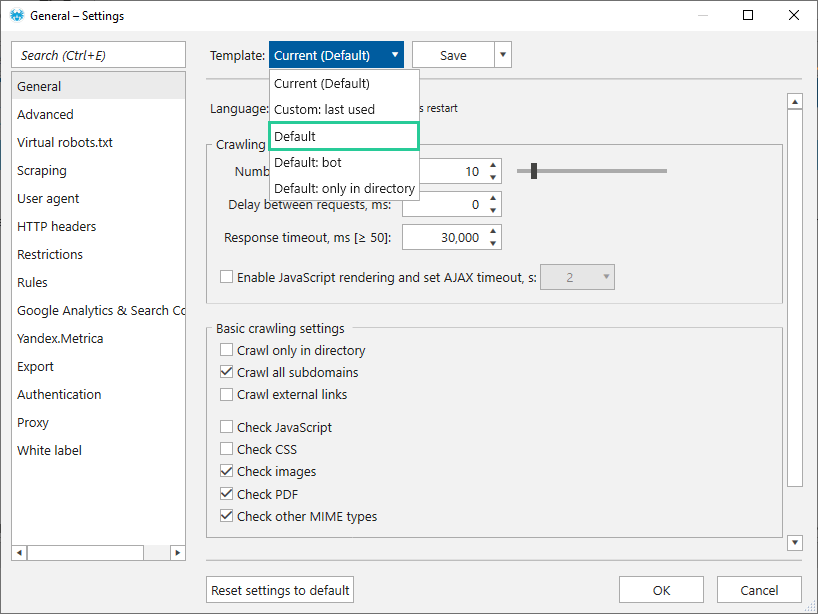
1.1. General settings
By default the ‘General‘ settings tab contains:
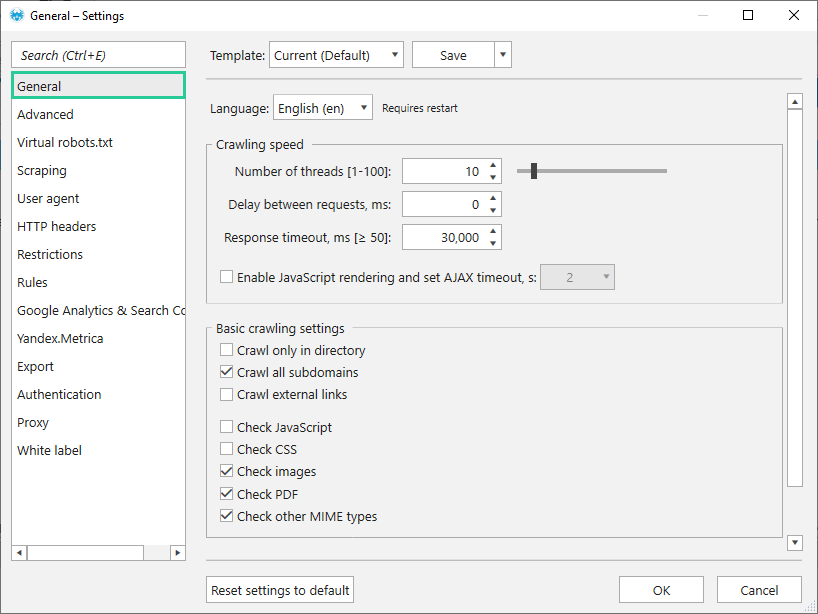
- Crawling in 10 threads → the optimal number of threads that most sites can handle. You can always change this number. Increase in the number of threads will speed up the crawling process, and also increase the server load, when the decrease in the number of threads will reduce the load.
Note that when you crawl a site with a large number of threads, the server on which the site is located, may not be able to withstand the load and begin to return an incorrect server response code or temporarily stop responding to requests.
- No delay between requests → the time interval in milliseconds which the crawler accesses the server. For load-sensitive servers or protected sites, we recommend setting a certain value so as not to overload the server, and imitate user behavior.
- Maximum waiting time for server response – 30 000 milliseconds. If the server did not respond during this time, the ‘Timeout‘ error will be shown in the ‘Status code‘ field, and the page will be considered broken.
- Enable JavaScript rendering → by default this feature is disabled. The feature allows you to crawl a URL with JavaScript code execution. This is necessary when part or all of the content is generated using JS frameworks and CSR (Client Side Rendering) technology. As the statistics show, the number of sites using CSR is much smaller than the number of sites that do not use this technology.
- Crawl all subdomains → allows considering subdomains as a part of the current website. All subdomains will be crawled and links to them will be considered internal.
- Check images → this feature allows you to collect common SEO parameters of images and detect ‘Broken images‘ and ‘Max image size‘ issues.
- Check PDF → allows collecting common SEO parameters.
- Check other MIME types → allows collecting common SEO parameters for RSS feeds, archives, documents, video and audio files.
1.2. Advanced settings
By default the ‘Advanced‘ settings tab contains:
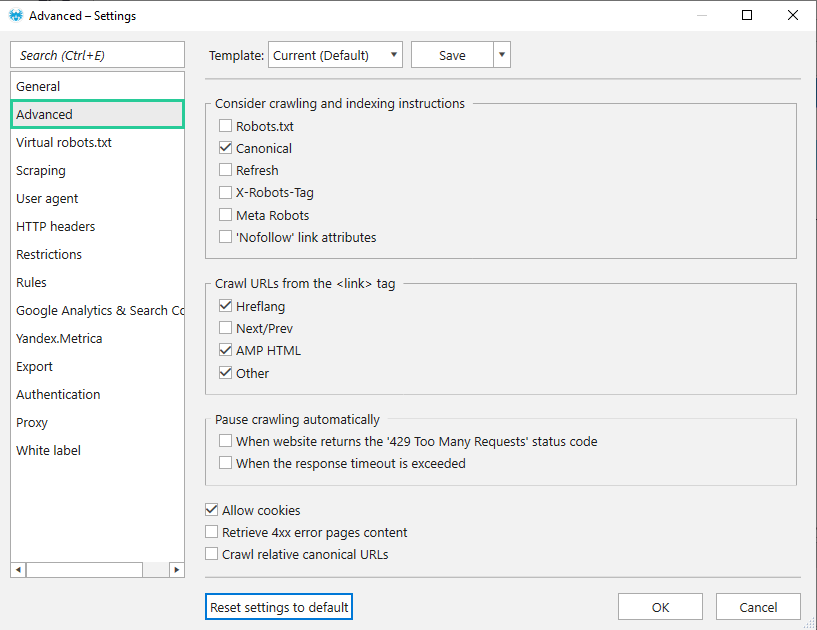
1. All indexing instructions, except Canonical, are disabled. So you don't risk missing important pages in the general analysis.
2. Crawl URLs from the tag:
- Hreflang → allows you to follow the links from hreflang attribute in the tag of the section of HTTP response header ‘Link: rel=”alternate”‘. This is necessary to ensure the correct settings of the hreflang attribute. Note that Netpeak Spider will crawl URLs in hreflang (both internal and external) despite ‘Crawl all external links‘ settings.
- AMP HTML → allows you to follow and check links where AMP technology is introduced.
- Other → allows you to check other URLs from the tags in the section. Note that this setting ignores the rel=”stylesheet” (CSS), hreflang, rel=”next/prev”, and rel=”amphtml” directives because they are covered by other settings.
3. Cookie file is allowed. Check in case the analyzed website is closed for all requests without a cookie file. Also, all requests will be tracked within one session. Otherwise, every new request will generate a new session.
1.3. User Agent
1.4 Restriction settings
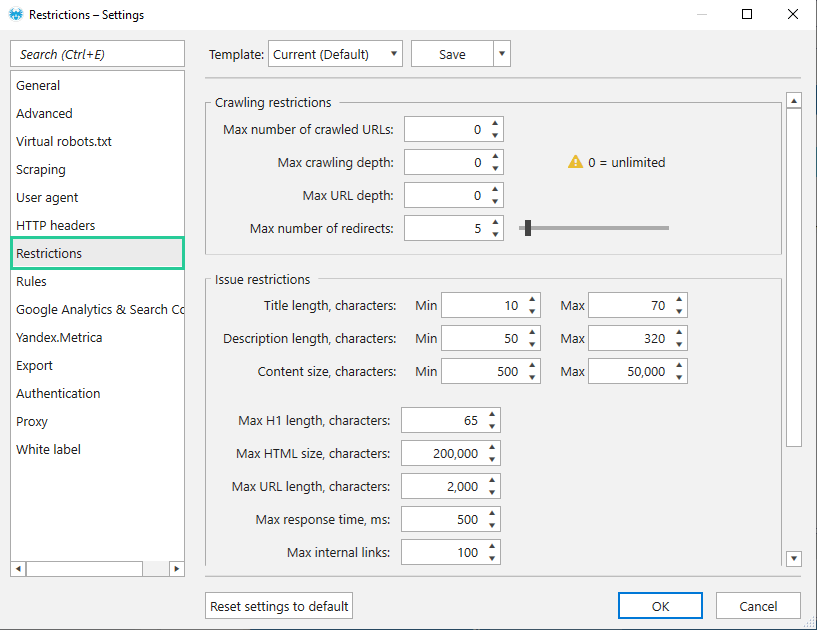
Max number of redirects – 5. In this case, Netpeak Spider will follow four redirects and the fifth one would be considered as an error. In the ‘Issue restrictions’ field you can adjust values for some parameters on your own to flexibly configure the program specifically for your current tasks. It was also based on the differences in requirements for each search engine.
2. Crawling
2.1. Crawling process
To start crawling, add the site address to the ‘Initial URL’ bar and press the ‘Start’ button.
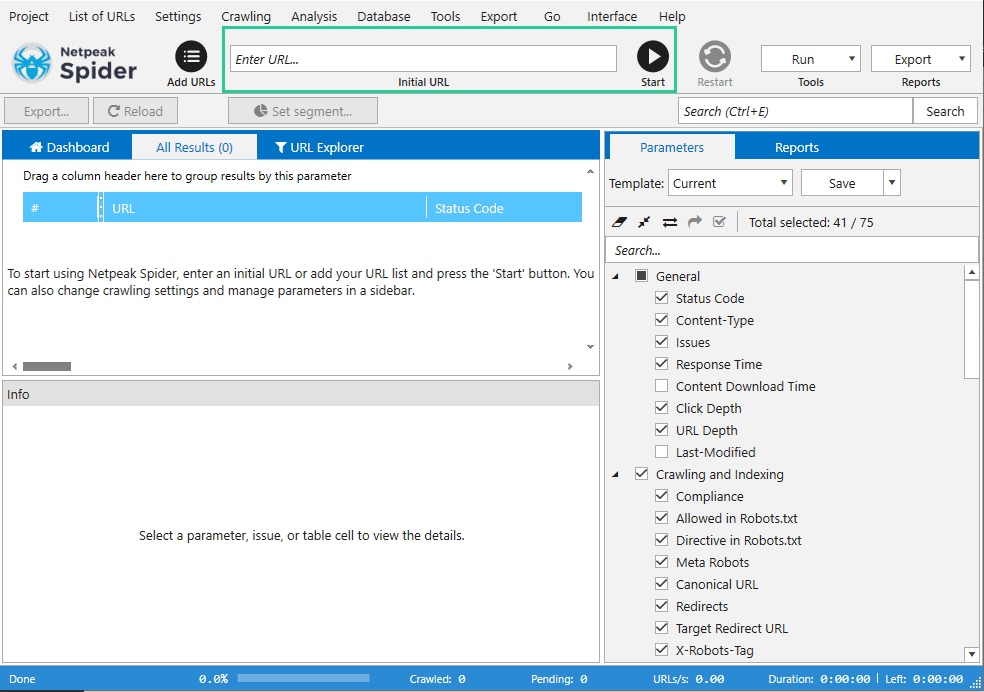
On the ‘Dashboard‘ tab, the program shows the current information about the crawling process and applied settings.
2.2. Changes in settings during crawling
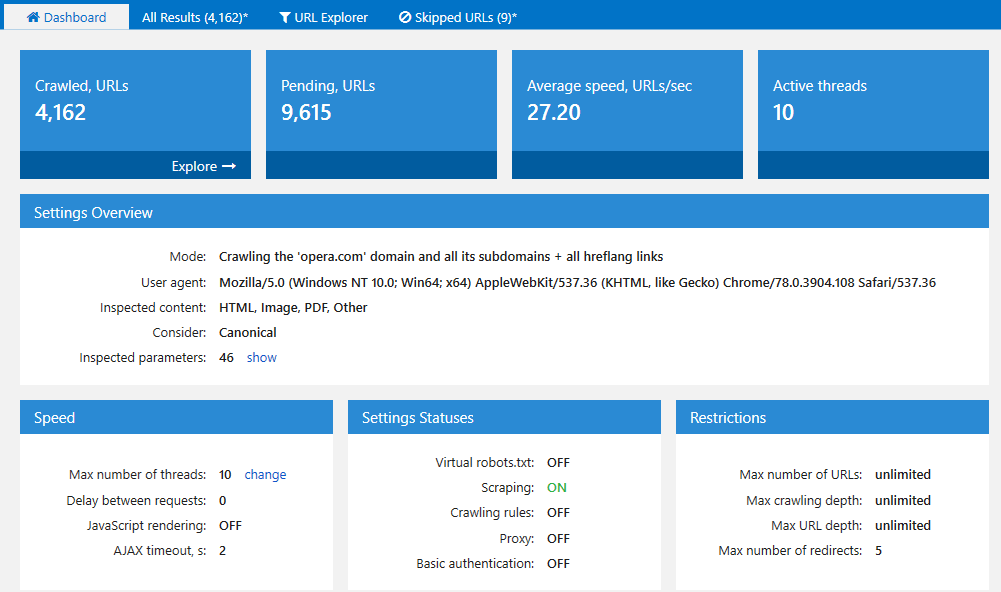
Only the number of threads can be changed directly during the crawling process. The changes will take effect immediately after you click ‘OK‘.
To change other settings (in the ‘Settings‘ of the main menu or on the side panel of the ‘Settings‘ tab), you need to suspend crawling by pressing the ‘Pause‘ button. Such changes will take effect when you resume crawling (‘Start‘ button) for uncrawled URLs. The results obtained before will remain unchanged.
The ‘Restart‘ button on the control panel will restore the results and resume crawling to get data for all URLs according to the new settings.
2.3. Pause and resume crawling
Crawling can be stopped at any stage by using the ‘Pause‘ button. To continue crawling (e.g. after changing settings), hit ‘Start‘, and it will start from where it had stopped.
2.4. Data analysis
When the crawling is finished (or paused), the data analysis will automatically begin: the program will detect duplicates, incoming links, Canonical chains and calculate internal PageRank, counting the issues according to configurations of parameters in the ‘Restrictions‘ settings tab. Also the program gets data from Google Search Console, Google Analytics, Yandex.Metrika, and queries from Google Search Console which rank in this search engine, if before crawling the corresponding parameters were enabled on the sidebar.
You can interrupt the analysis anytime, and resume in the ‘Analysis‘ menu on a control panel.
3. Saving the project and exporting the results

When the crawling is finished or stopped, you can save the project. In order to save the project, select ‘Save... ‘ (Ctrl+S), or ‘Quick Save‘ (Ctrl+Shift+S) on the control panel in the ‘Project‘ dropdown menu.
Saving a project via ‘Save... ‘ allows you to specify a directory and create a custom file name. When saving via ‘Quick Save‘, the project would be saved in the default folder (usually the Desktop one), and under the default name.
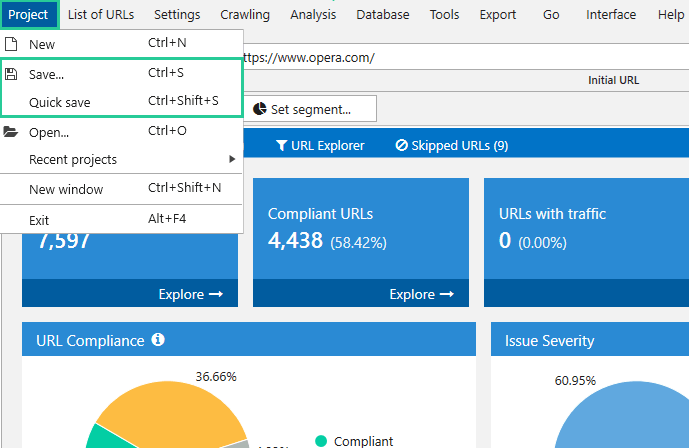
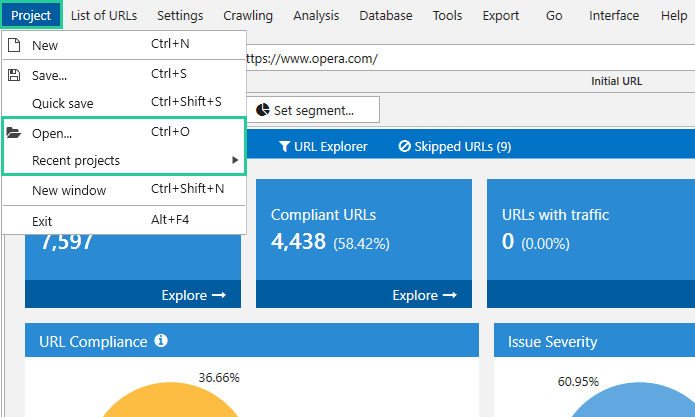
If necessary, continue crawling later or on another device:
1. Save the project.
2. Open a saved project in the ‘Project‘ → ‘Recent projects‘ or ‘Open‘ (Ctrl+O) on the control panel.
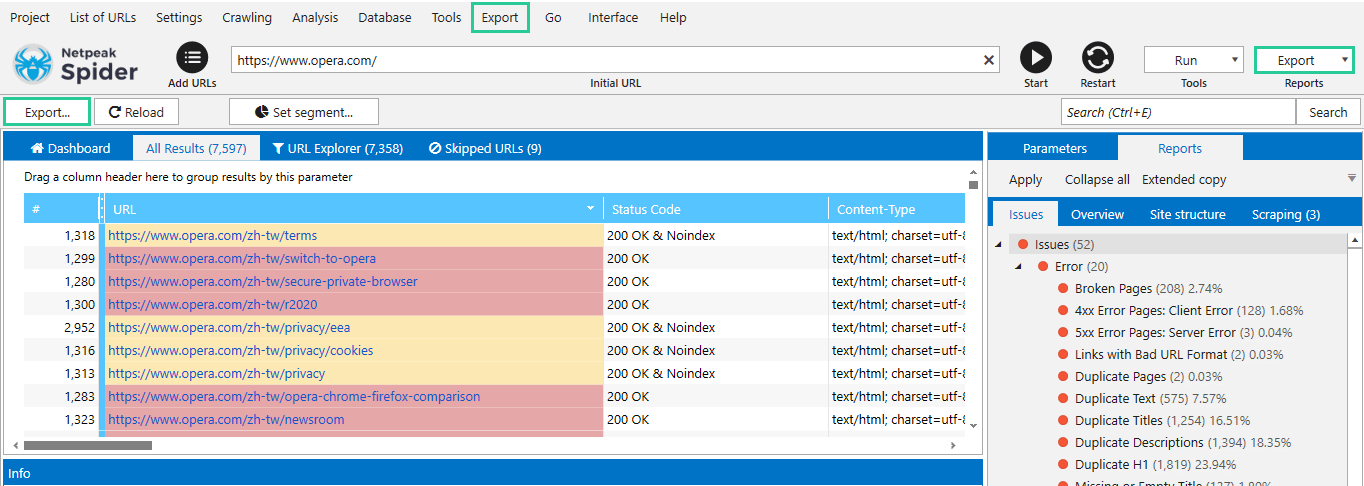
To export all or part of the results for further work you can:
- Choose the necessary report template in the ‘Export‘ menu of the control panel or in the main menu. Download current results from ‘Dashboard’ via the ‘Export... ‘ button in the upper left corner. This method is useful when you apply filters, or work within database tables.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article