1. Предустановленные настройки по вкладкам
1.1. Основные настройки
1.3. Настройки User Agent
2. Сканирование
2.1. Начало и ход сканирования
2.2. Изменение настроек во время сканирования
2.3. Пауза и возобновление сканирования
2.4. Анализ данных
3. Сохранение проекта и экспорт результатов
Netpeak Spider даёт широкий выбор пользовательских настроек и их шаблонов. В этой статье мы расскажем, как быстро начать сканирование, а также о настройках по умолчанию в Netpeak Spider.
1. Настройки по умолчанию
Шаблон настроек по умолчанию подходит для общего анализа состояния сайта и решения стандартных SEO-задач. Он затрагивает вкладки настроек:
- «Основные»,
- «Продвинутые»,
- «Виртуальный robots.txt»,
- «Парсинг»,
- «User Agent»,
- «Ограничения»,
- «Правила».
Вы всегда сможете вернуться к шаблону настроек по умолчанию, выбрав его из выпадающего списка шаблонов в верхней части окна настроек — он будет применён к перечисленным выше вкладкам настроек программы.
1.1. Основные настройки
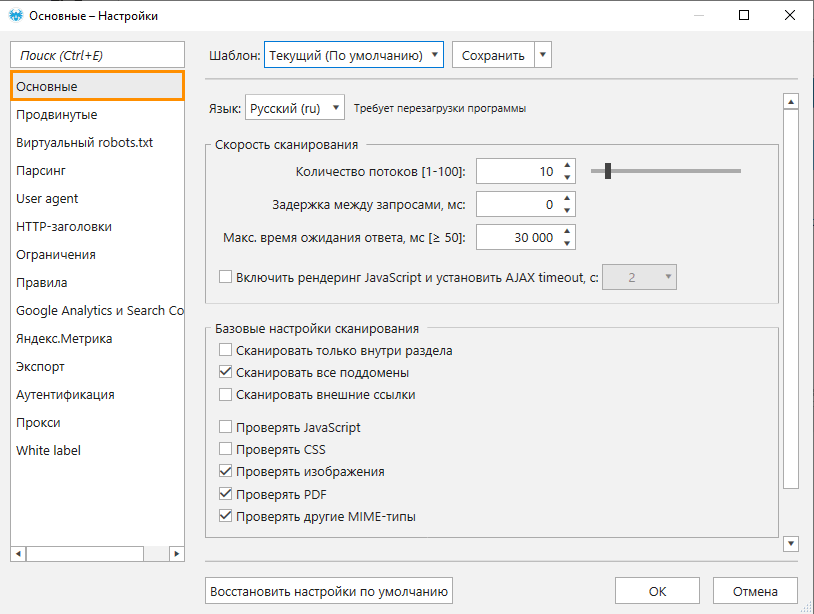
На вкладке основных настроек по умолчанию выставлено:
- Сканирование в 10 потоков → оптимальное количество потоков, с которым справляется большинство сайтов. Вы всегда можете изменить их количество: увеличение ускорит процесс сканирования, но повысит нагрузку на сервер, а уменьшение приведёт к снижению нагрузки.
- Будьте осторожны! При сканировании сайта на большом количестве потоков сервер, на котором расположен сайт, может не выдержать нагрузку и начать отдавать некорректный код ответа сервера или временно перестать отвечать на запросы.
- Отсутствие задержки между запросами → это промежуток времени в миллисекундах, через который краулер обращается к серверу. Рекомендуем устанавливать задержку при сканировании чувствительных к нагрузке серверов или защищённых сайтов, чтобы не перегружать сервер или имитировать поведение пользователя.
- Максимальное время ожидания ответа сервера — 30 000 миллисекунд. Если за это время краулер не получит ответ сервера, в поле «Код ответа сервера» отобразится ошибка «Timeout», а страница будет считаться битой.
- Включить рендеринг JavaScript → по умолчанию функция отключена. Она позволяет сканировать URL с выполнением JavaScript-кода. Это необходимо, когда часть контента или весь контент сайта генерируется с использованием JS-фреймворков и технологии CSR (Client Side Rendering — выполнение на стороне клиента). По умолчанию опция отключена, так как сайтов, не использующих CSR технологию, преобладающее количество.
- Сканирование всех поддоменов → позволяет учитывать поддомены как часть анализируемого сайта. Все поддомены будут просканированы, а ссылки на них — считаться внутренними.
- Проверять изображения → необходимо для сбора основных SEO-параметров по картинкам и поиска ошибок по ним. Ссылки на изображения будут добавлены в основную таблицу «Все результаты».
- Проверять PDF → для сбора SEO-параметров о файлах этого формата.
- Проверять другие MIME-типы → архивы, RSS-фиды, видео и аудио файлы и пр.
1.2. Продвинутые настройки
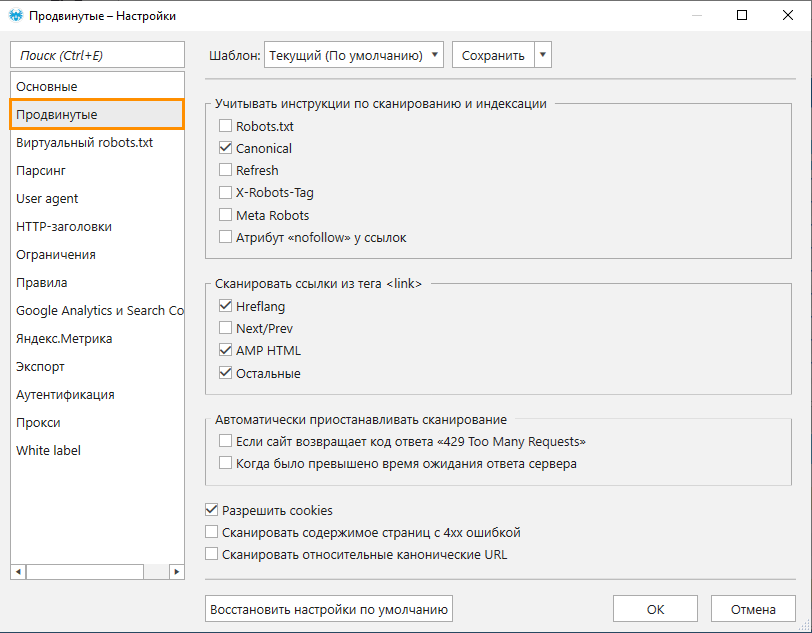
На этой вкладке по умолчанию стоят следующие настройки:
Отключён учёт всех инструкций по индексации, кроме Canonical. Так вы не рискуете упустить важные страницы из общего анализа.
Включено сканирование ссылок из тега :
- Hreflang → позволяет переходить по ссылкам из атрибута hreflang в теге блока или в HTTP-заголовке «Link: rel=”alternate”» — это необходимо для проверки корректности настройки hreflang. Обратите внимание, что Netpeak Spider будет сканировать все URL из hreflang (как внутренние, так и внешние) вне зависимости от настройки «Сканировать внешние ссылки».
- AMP HTML → позволяет находить и проверять страницы, на которых внедрена технология AMP.
- Остальные → для проверки всех URL из остальных тегов в блоке и их добавления в таблицу результатов.
3. Разрешены cookie-файлы. Это сделано для тех случаев, когда сайт не отдаёт информацию при обращении краулера без принятия cookie-файлов. Cookie-файлы действительны только в рамках одной сессии.
1.3. User Agent
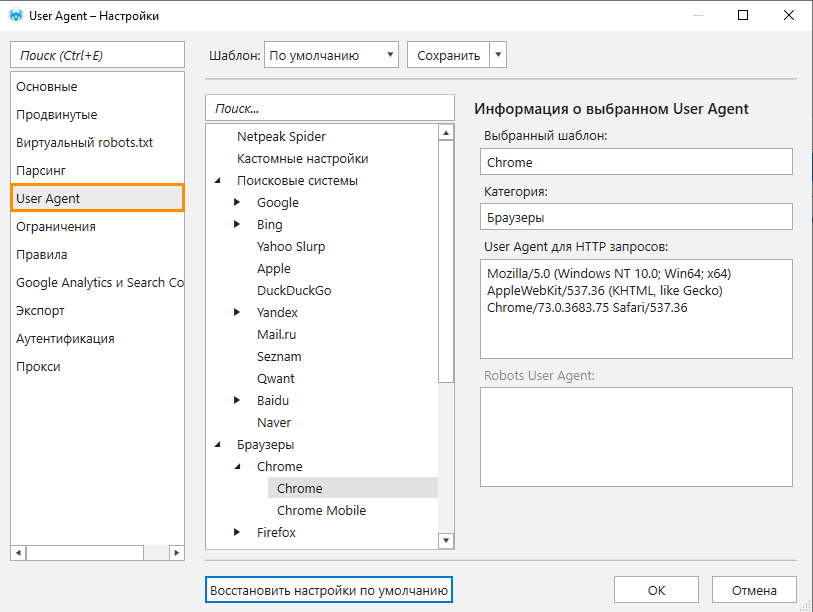
По умолчанию Netpeak Spider сканирует сайт, используя Google Chrome как User Agent для полноценного отображения результатов сканирования, так как зачастую страницы для него открыты и отдают корректный код ответа сервера.
1.4. Настройки ограничений
По умолчанию количество сканируемых страниц, вложенность и глубина сканирования не ограничены.
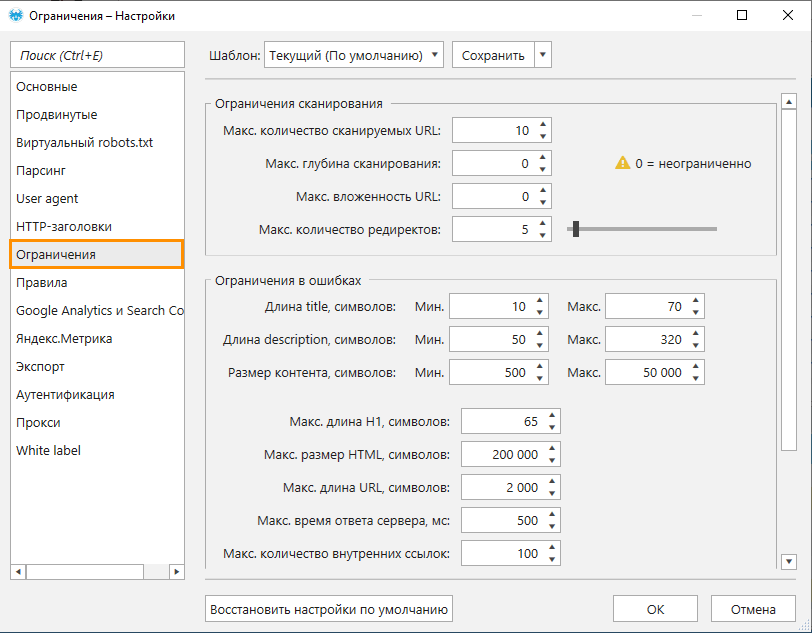
Максимальное количество редиректов по умолчанию — 5. В данном случае программа будет переходить максимум по четырём редиректам, а пятый — считать ошибкой.
В поле «Ограничения в ошибках» вы можете самостоятельно задавать значения для некоторых параметров, чтобы максимально гибко настроить программу под ваши задачи. Это сделано также по причине разных требований к определённому параметру для каждой поисковой системы.
2. Сканирование
2.1. Начало и ход сканирования
Для быстрого запуска сканирования добавьте адрес сайта в поле «Начальный URL» и нажмите «Старт» на панели управления.

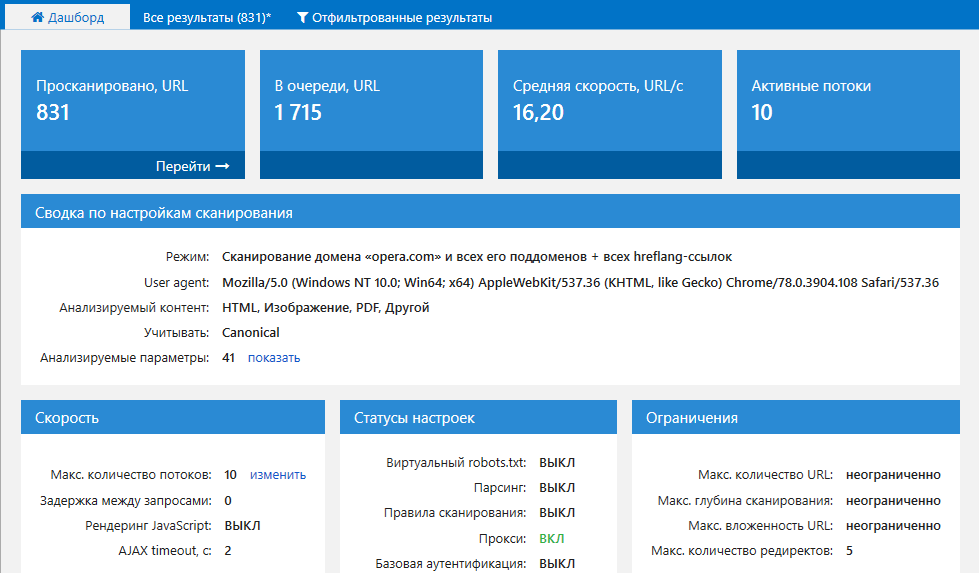
На вкладке «Дашборд» основной панели отображается информация о ходе сканирования и данные о настройках.
2.2. Изменение настроек во время сканирования
В процессе сканирования можно изменить только количество потоков. Изменения вступят в силу сразу после нажатия на кнопку «OK».
Чтобы изменить другие настройки, необходимо приостановить сканирование кнопкой «Пауза». Тогда изменения вступят в силу после возобновления сканирования (кнопка «Старт») для непросканированных URL. Результаты, полученные прежде, останутся без изменений.
Кнопка «Рестарт» на панели управления очистит результаты и запустит сканирование сайта заново согласно новым настройкам.
2.3. Пауза и возобновление сканирования
Сканирование можно остановить на любом этапе с помощью кнопки «Пауза». Чтобы продолжить сканирование (например, после изменения настроек), нажмите «Старт»: оно запустится с того места, где остановилось.
2.4. Анализ данных
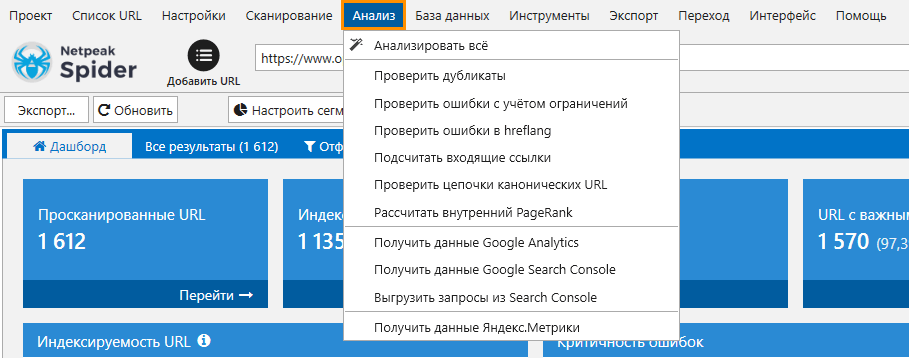
По окончании сканирования (или при нажатии «Пауза») автоматически начнётся анализ данных: дубликатов, входящих ссылок, цепочек Canonical и внутреннего PageRank, подсчёт ошибок согласно конфигурациям параметров из вкладки настроек «Ограничения». Также программа получит данные с сервисов Google Search Console, Google Analytics. После завершения сканирования или остановки проекта на паузу, произойдёт выгрузка запросов из Google Search Console, по которым ранжируется каждая страница. Данные по сервисам подтянутся в программу, если перед сканированием соответствующие параметры были включены на боковой панели.
Анализ можно прерывать и возобновлять в любой момент → это делает через меню «Анализ».
3. Сохранение проекта и экспорт результатов
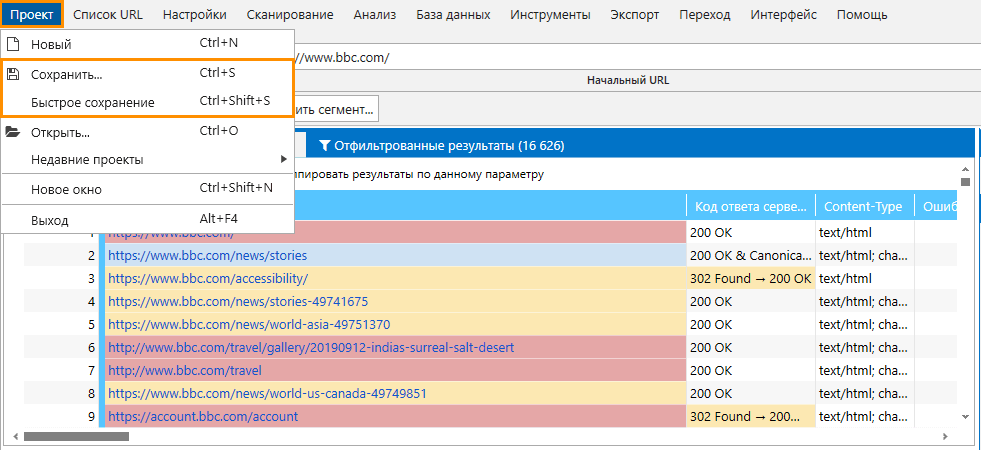
По завершении или при остановке сканирования вы можете сохранить проект. Для этого выберите «Сохранить... » (Ctrl+S) или «Быстрое сохранение» (Ctrl+Shift+S) на панели управления в выпадающем меню «Проект».
Сохранение проекта через опцию «Сохранить... » позволяет указать директорию и самостоятельно выбрать имя файла. При сохранении через «Быстрое сохранение» проект сохраняется в дефолтную папку (обычно это рабочий стол) и с дефолтным названием.
При необходимости продолжить сканирование можно позже или на другом устройстве. Для этого:
- Сохраните проект.
- Откройте сохранённый проект с помощью меню «Проект» → «Последние проекты» или «Открыть» (Ctrl+O).
Алгоритм экспорта всех или части полученных результатов выглядит следующим образом:
- В меню «Экспорт» на панели управления или в главном меню выберите необходимый шаблон отчёта.
- Выгрузите результаты текущей таблицы с помощью кнопки «Экспорт» слева над таблицей результатов. Этот способ особенно удобен в случае применённых фильтров или работы внутри таблиц модуля «База данных».
Статья помогла?
Отлично!
Спасибо за ваш отзыв
Извините, что не удалось помочь!
Спасибо за ваш отзыв
Комментарий отправлен
Мы ценим вашу помощь и постараемся исправить статью