
Постоянная работа над созданием и повышением качества контента — одна из самых сложных задач в рамках комплексного продвижения сайта. Как найти нужную тему для статьи, как сделать её более интересной и виральной? Сосредоточив внимание исключительно на собственном сайте, вам будет тяжело найти ответы на эти вопросы, а потому мы предлагаем вам обратиться к конкурентам за помощью. Да, вы не ослышались: мы предлагаем воспользоваться опытом ваших прямых конкурентов и в автоматическом режиме выяснить, какие из их материалов пользуются наибольшим успехом у пользователей (и почему).
В рамках данного поста на примере медиапортала businessoffashion.com мы продемонстрируем:
- как выявить наиболее популярные материалы на сайтах ваших конкурентов,
- как в автоматическом режиме определить их показатели вовлечённости,
- как определить средний объём самых популярных постов,
- а также как почерпнуть у конкурентов идеи для своих будущих публикаций.
Для выполнения этих задач мы воспользуемся Netpeak Spider. Часть параметров мы определим и отфильтруем в рамках базового сканирования сайта (или раздела, где размещён анализируемый контент), часть — при помощи нескольких параллельных потоков парсинга.
1. Показатели вовлечённости: настройка парсинга
В рамках сканирования сайтов-конкурентов мы будем настраивать два параллельных потока парсинга — по количеству шейров и комментариев. В зависимости от выбранного сайта анализируемые показатели будут отличаться: это также могут быть лайки (апвоуты), просмотры и прочие метрики.
Чтобы настроить парсинг, выполните следующие действия:
- Откройте одну из страниц с контентом.
- Найдите счётчик шейров (комментариев, просмотров) и выделите его.
- Кликните по нему правой кнопкой мыши и нажмите «Просмотреть код» (или «Inspect», если вы используете англоязычный интерфейс).
- В открывшемся окне с исходным кодом найдите элемент, отвечающий за показ количества шейров (при наведении он будет подсвечен).
- Кликните по нему правой кнопкой мыши и выберите в контекстном меню «Копировать» → «Копировать XPath».
Тип данных, с помощью которых производится парсинг (Xpath, RegExp, CSS-селектор), может отличаться в зависимости от особенностей строения сайта. В большинстве случаев с этой задачей помогает справиться именно XPath.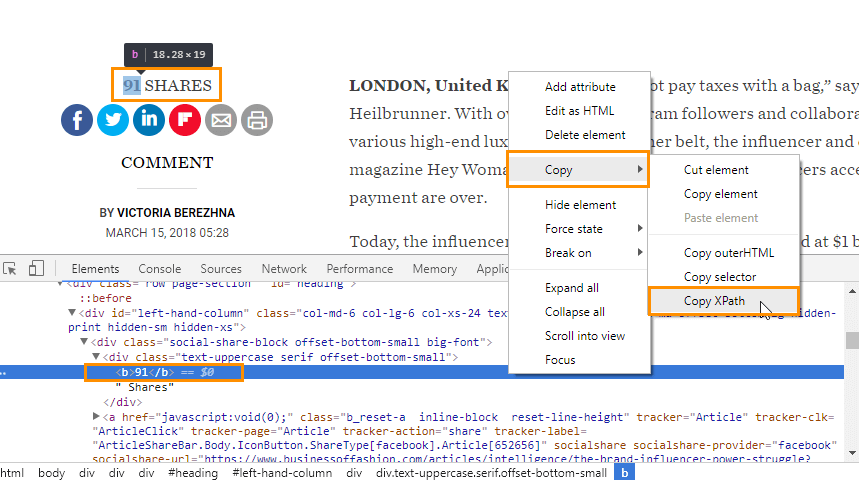
- Запустите Netpeak Spider и откройте «Настройки» → «Парсинг» и отметьте флажком «Использовать парсинг HTML-данных».
- Для удобства обработки задайте имя для потока номер 1 («Комментарии», «Просмотры», «Шейры» и т.п.).
- Выберите тип данных (XPath) и область поиска (Внутренний текст).
- В строку поиска вставьте полученный отрезок кода с сайта.
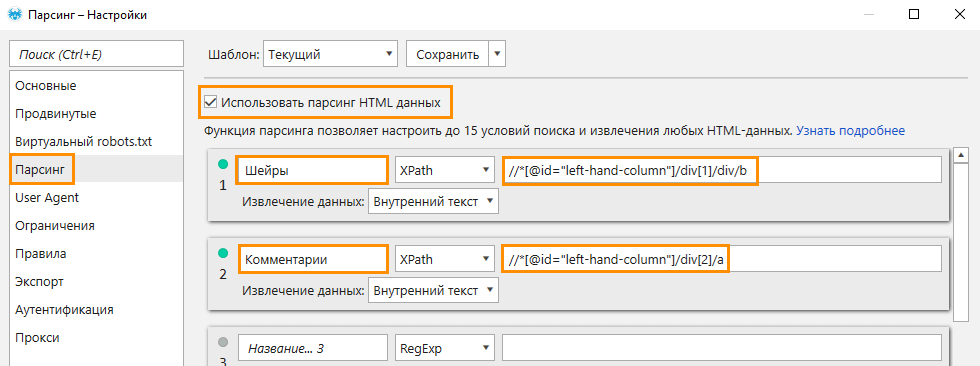
- Повторно проделайте всё, что описано в пунктах со второго по девятый для всех остальных показателей вовлечённости, которые вас интересуют, и создайте для них дополнительные потоки парсинга.
- В окне настроек перейдите на вкладку «Основные».
Анализировать контент конкурентов вы можете даже в бесплатной версии Netpeak Spider без ограничений по времени использования, в которой также доступны многие базовые функции программы.
Чтобы начать пользоваться бесплатным Netpeak Spider, просто зарегистрируйтесь, скачайте и установите программу — и вперёд! ?
Зарегистрироваться и установить бесплатную версию
P.S. Сразу после регистрации у вас также будет возможность потестировать весь платный функционал, а затем сравнить все наши тарифыи выбрать для себя подходящий.2. Настройка и запуск сканирования: базовые параметры
Прежде чем запустить сканирование и парсинг, нужно задать несколько базовых параметров:
- На вкладке «Общие» найдите «Базовые настройки сканирования». Отключите сканирование изображений, PDF-файлов, CSS, JavaScript и прочих MIME-типов.
- Выберите режим сканирования. Если вас интересует контент со всего сайта, то выберите опцию «Сканировать все поддомены». Если же вас интересует определенный раздел или категория — выберите «Сканировать в рамках директории». Для BoF мы выбрали режим сканирования в рамках раздела /articles/, а также задали ограничение количества анализируемых страниц (1000 URL).
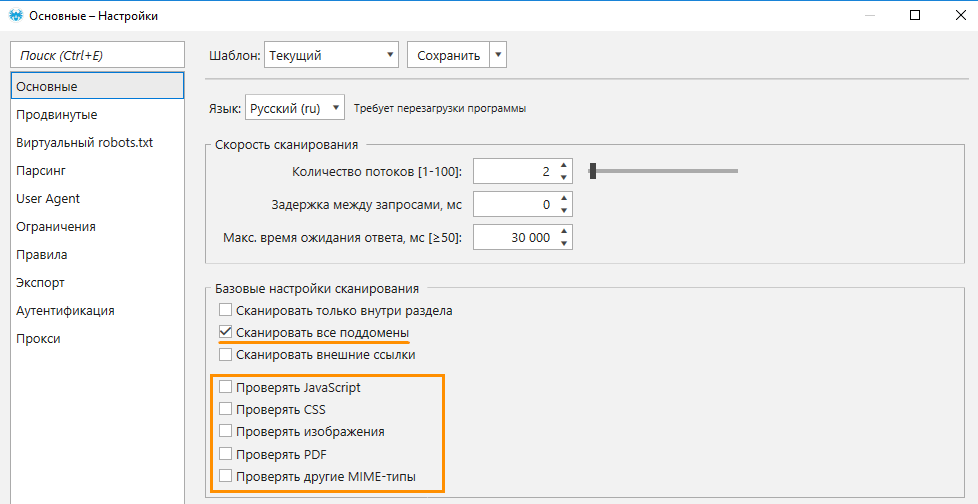
- Настройте пользовательские «Правила», если вас интересуют какие-то специфические страницы, не ограниченные одной директорией. Эта процедура подробно описана в нашей статье, посвящённой парсингу цен. Сохраните настройки.
- В основном окне программы откройте вкладку «Все результаты» и кликните правой кнопкой мыши по строке с названиями параметров (выкрашена в голубой цвет). Уберите маркеры со всех параметров, кроме «Title», «Description», «Количество слов в <p>», «Количество символов в <p>» и других потенциально полезных показателей.
- Запустите сканирование.
3. Выгрузка и анализ данных
Благодаря настройкам сканируемых параметров итоговая таблица результатов сканирования содержит исключительно те данные, которые требуются для построения своей контентной стратегии (пункт 4 раздела 2). Основываясь на них, можно сделать вывод об оптимальном объёме контента, а также о построении максимально выигрышных заголовков и описаний.
После завершения сканирования экспортируйте полученные данные в виде удобной таблицы. Для этого нажмите на кнопку «Экспорт», расположенную слева над таблицей с результатами поиска.
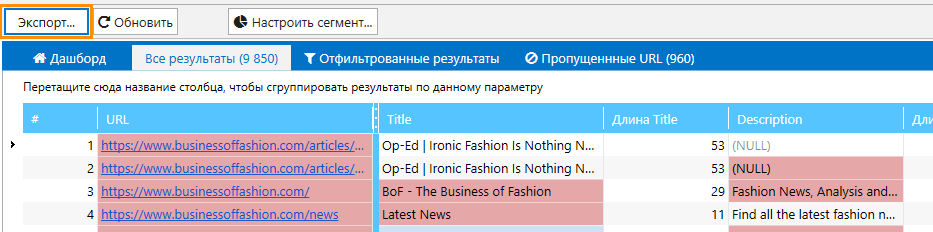
Полученный отчёт будет содержать в себе данные обо всех стандартных параметрах сканирования, которые вы выберете, а также данные парсинга.
В том случае, если вам нужен отдельный отчёт для парсинга, вы можете поступить следующим образом:
- На боковой панели справа откройте вкладку «Сканирование» → «Парсинг».
- Для просмотра таблицы с результатами парсинга нажмите на кнопку «Все результаты».
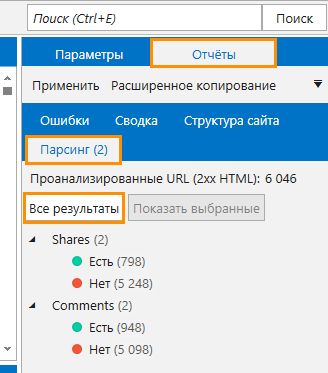
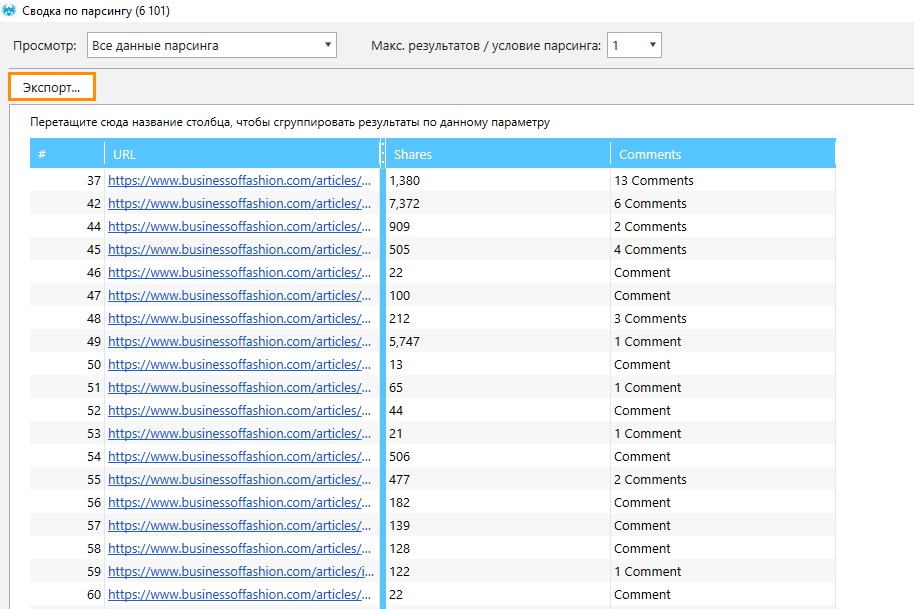
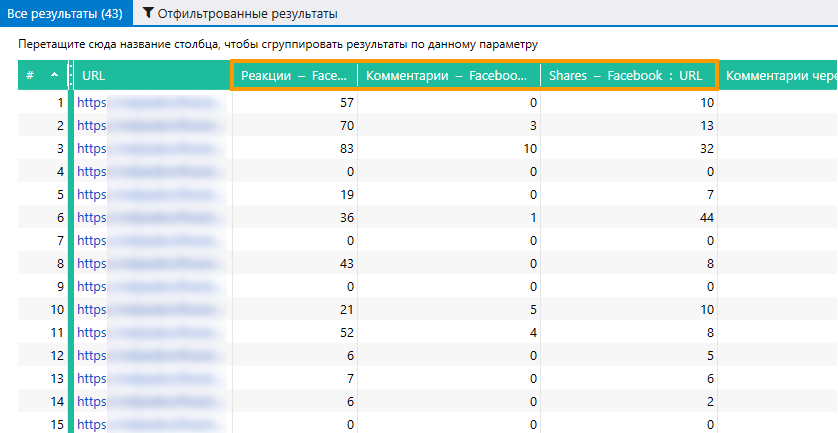
В открывшемся окне отображаются исключительно те данные, что были получены в процессе кастомного парсинга (в нашем случае — показатели числа комментариев и шейров). Сортируя результаты по тому или иному показателю, вы можете увидеть посты с наибольшим (или наименьшим) количеством комментариев, шейров, лайков или просмотров.
По итогу сканирования businessoffashion.comмы отсортировали полученные данные и получили топ наиболее популярных материалов. Среди них мы выделили следующих лидеров по количеству шейров и комментариев: - Miroslava Duma and Ulyana Sergeenko Accused of Racism, Homophobia and Transphobia: 77 комментариев.
- Gucci Bans Fur: ‘It’s Not Modern’: 44 888 шейров.
Однако, не стоит делать выводы, полагаясь лишь на абсолютных лидеров: мы рекомендуем анализировать мало-мальски репрезентативный объём публикаций с наибольшим количеством шейров и комментариев.
Исходя из полученных данных мы можем выделить определённые параметры максимально востребованного контента: его тематику, объём (количество слов и/или символов) и способ составления Title и Description.
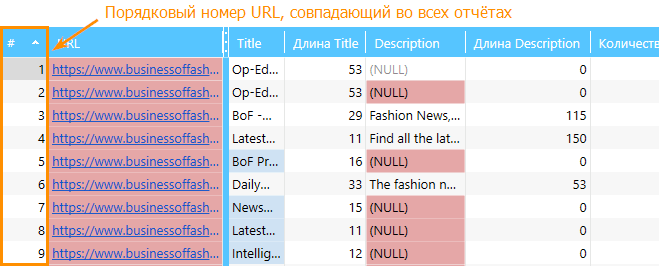
Отдельно cтоит отметить, что если вы оперируете двумя отчётами по отдельности, учитывайте, что каждой из страниц присваивается порядковый номер, совпадающий в обеих таблицах, что позволяет упростить процесс работы с данными.
Если на блоге / сайте нет счётчиков шейров, тогда переходите в Netpeak Checker → он покажет количество шейров из Facebook. Для этого нужно:
- Просканировать в Netpeak Spider сайт, чтобы получить URL страниц.
- Перенести собранные адреса в Checker удобным для вас способом.
- Перейти на вкладку настроек «Facebook» и вставьте токен Facebook.
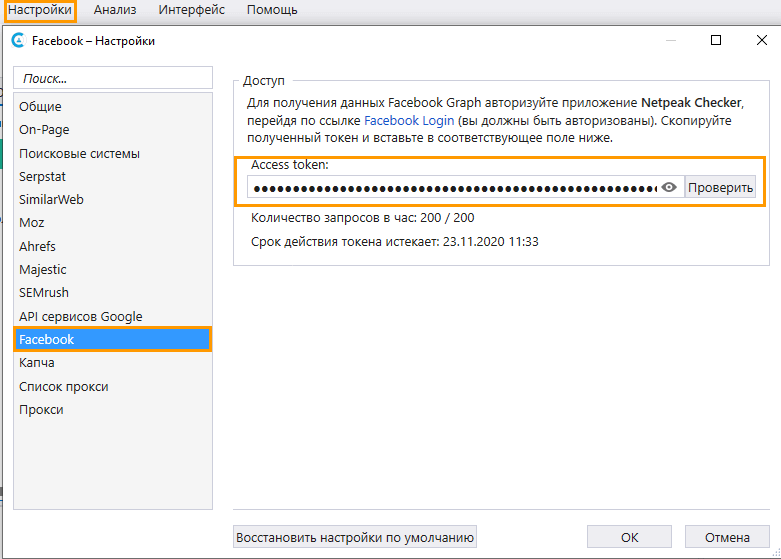
- На боковой панели программы выбрать параметр «Facebook» → «Shares». При необходимости вы можете отметить другие параметры, например, комментарии и реакции, данные из разметки Open Graph.
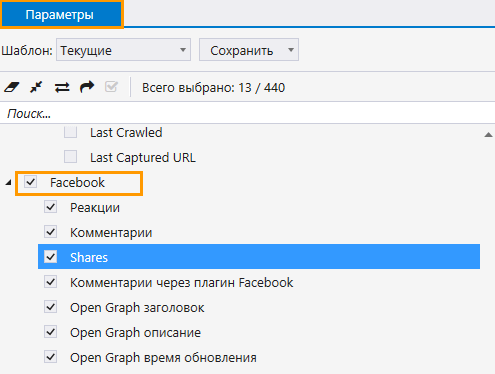
- Запустить сканирование.
- По окончании все полученные данные вы увидите в основной таблице.
Подводим итоги
Для того, чтобы проанализировать контент с сайтов ваших конкурентов и выделить наиболее популярный (самый просматриваемый, комментируемый, виральный), необходимо совершить следующие действия:
- Определить, какие из представленных показателей вовлечённости вам требуются в первую очередь.
- Скопировать их XPath.
- Определить режим сканирования и выставить соответствующие настройки Netpeak Spider.
- Запустить сканирование и парсинг.
- Отфильтровать полученные данные.
- Экспортировать результаты сканирования и парсинга и сделать все соответствующие выводы
А какой способ анализа контента конкурентов предпочитаете вы?
Пользуетесь ли подобной методологией? Поделитесь своим опытом с нами: возможно, он послужит основой для нашего следующего материала ;)
Если после прочтения у вас остались вопросы, оставляйте их в комментариях: мы с удовольствием на них ответим.
Понравился кейс? Давайте лично обсудим все детали и преимущества Netpeak Spider

Статья помогла?
Отлично!
Спасибо за ваш отзыв
Извините, что не удалось помочь!
Спасибо за ваш отзыв
Комментарий отправлен
Мы ценим вашу помощь и постараемся исправить статью