1. Types of scraping parameters.
2. How to apply scraping feature.
3. Configuration of scraping parameters.
4. Display of scraping parameter in a sidebar.
5. Scraping results.
Scraping allows you to find and extract necessary data from a website. It is possible to set up to 100 custom parameters for searching and extracting data, for instance, to verify the implementation of analytics settings, microdata, meta tags for social media, and also to extract huge amounts of data from HTML pages (prices, contact data, metrics, etc.).
1. Types of scraping parameters
The program has four types of scraping parameters:
- Contains → searching and counting the number of occurrences of the required phrase on a page.
- RegExp → collects all values matching the specified regular expression. It allows greatly enhancing search capabilities but requires basic knowledge of regular expressions.
- CSS-selector → collects all values from required HTML elements based on specified CSS-selector.
- XPath → collects all values from required HTML elements based on specified XPath.
2. How to apply scraping feature
Follow the instructions below to start scraping process:
1. Go to the ‘Settings → ‘Scraping.‘
2. Tick the ‘HTML Scraping‘ checkbox.
3. Set up necessary parameters.
4. Start crawling.
3. Scraping parameters configuration
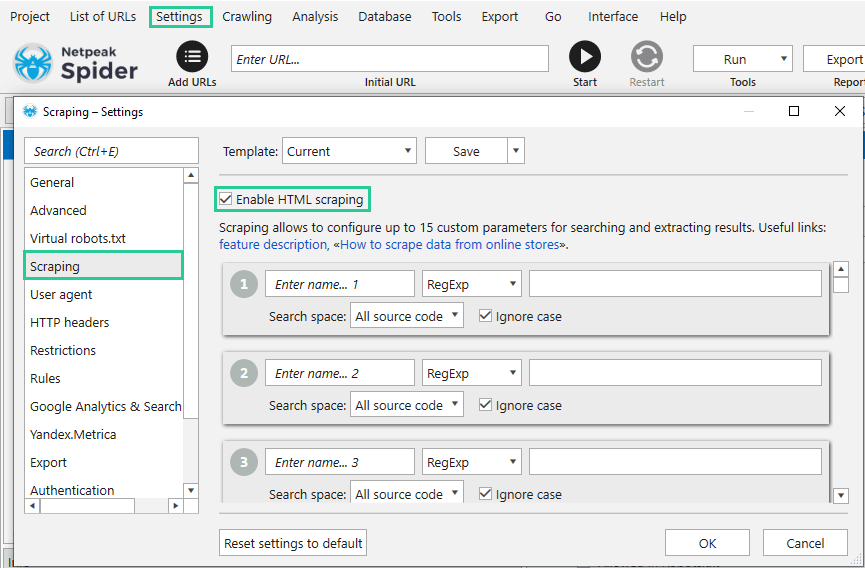
Custom scraping parameters contain the following fields and buttons:
Name → an optional field that helps you navigate through results when several parameters are set.
Search Method → there are four possible types of scraping that you can choose from the dropdown list → Contains, RegExp, CSS-selector, or XPath.
Search expression → an expression that will help extract required data. Search expression depends on the chosen search type. Regardless of the selected type, every expression is validated, so the program will quickly show you whether the entered expression is correct or not.
Search space → can be selected only for the ‘Contains‘ and ‘RegExp‘ methods. If you click on it, you will see two options:
- All source code → search for necessary expression on a page including all its HTML tags.
- Only text (excluding HTML tags) → search for necessary expression only inside the text on a page.
Data extraction → this field is available for CSS-selectors and XPath. It can have one of the following parameters:
- Inner text → text extraction from the specified HTML element and its child elements, excluding HTML tags.
- Inner HTML content → HTML content extraction from the specified element including inner HTML code.
- Entire HTML element → HTML content extraction from the specified element including the HTML code of inner elements and specified element.
- Attribute → content extraction of the specified attribute.
Ignore case → available for ‘Contains‘ and ‘RegExp‘. By default, the crawler will not take into account the case which makes it easy to find necessary phrases.
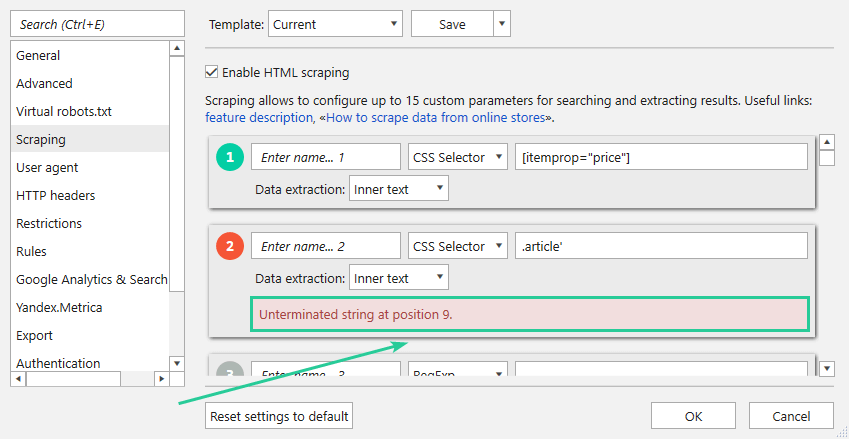
Please note that the program contains the validation of expressions. If the expression (scraping condition) was written according to syntax rules, you will see a green circle in the field with the expression. Otherwise, the expression will be highlighted red and under the expression field you will see an error saying what you need to fix.
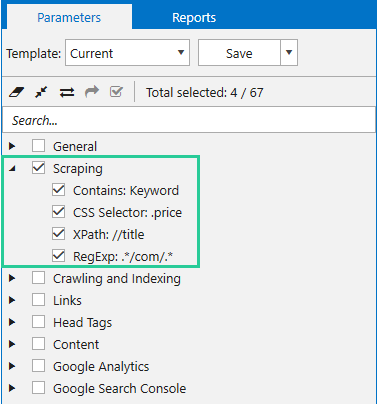
4. Display of scraping parameter in a sidebar
Once the scraping parameters are set, they will appear as custom parameters in a sidebar on the ‘Parameters‘ tab. If names were not added for parameters, you will see scraping expressions instead of parameter names.
5. Scraping results
The scraping results are available in the ‘Reports → Scraping‘ in the sidebar. Each search parameter is split into two categories depending on the presence of the required values – ‘Found‘ and ‘Not found‘. Click on the ‘Show all results‘ to see the full report or choose the necessary category and click on the ‘Show selected‘ to see the report displaying a list of pages that contain the selected value. Full scraping reports can also be viewed using the ‘Database‘ button in the main program menu.
We also recommend you to check out the article ‘Comprehensive Guide: How to Scrape Data from Online Stores With a Crawler’ to understand how to configure scraping parameters.
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article