1. Встановлені налаштування за вкладками:
1.1. Основні налаштування
1.3. Установки User Agent
2. Сканування:
2.1. Початок та хід сканування
2.2. Зміна налаштувань під час сканування
2.3. Пауза та відновлення сканування
2.4. Аналіз даних
3. Збереження проекту та експорт результатів
Netpeak Spider дає широкий вибір налаштувань користувача та їх шаблонів. У цій статті ми розповімо, як швидко почати сканування, а також про налаштування за замовчуванням Netpeak Spider.
1. Налаштування за замовчуванням
Шаблон налаштувань за замовчуванням підходить для загального аналізу стану сайту та вирішення стандартних SEO-задач. Він об’єднує вкладки налаштувань:
- Основні,
- Просунуті,
- Віртуальний robots.txt,
- Парсинг,
- User Agent,
- Обмеження,
- Правила.
Ви завжди зможете повернутися до шаблону налаштувань за замовчуванням, вибравши його зі списку шаблонів у верхній частині вікна налаштувань — він буде застосований до перелічених вище вкладок налаштувань програми.
1.1. Основні налаштування
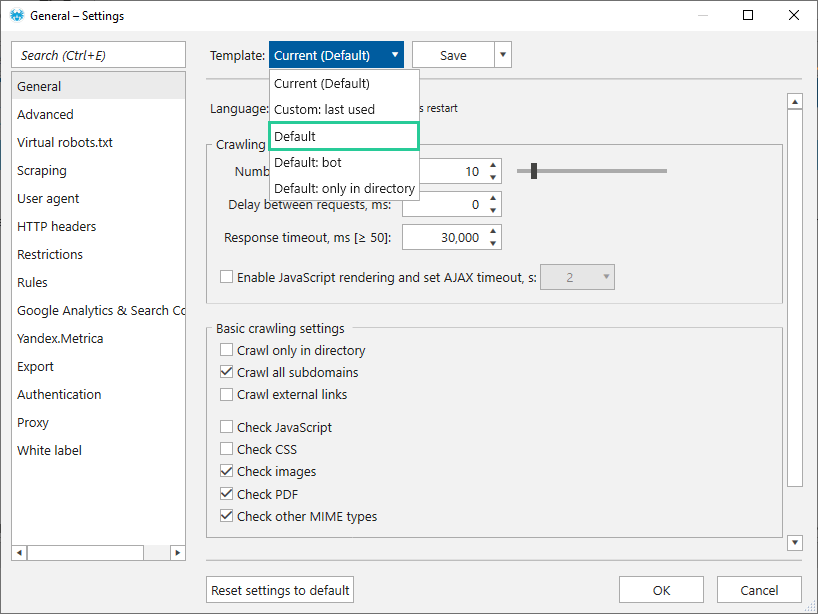
На вкладці основних налаштувань за замовчуванням виставлено:
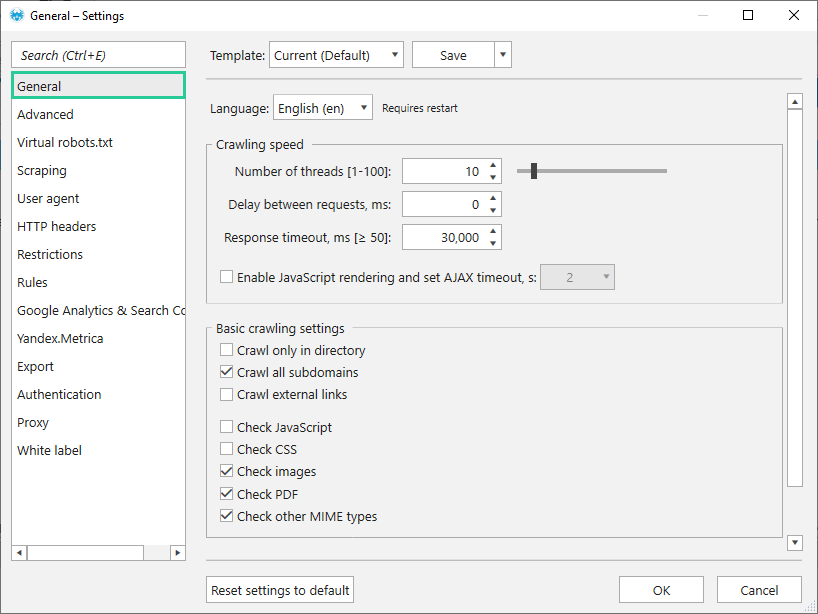
- Сканування в 10 потоків → оптимальна кількість потоків, з якою справляється більшість сайтів. Ви завжди можете змінити їх кількість: збільшення прискорить процес сканування, але підвищить навантаження на сервер, а зменшення призведе до зниження навантаження.
- Будьте обережні! При скануванні сайту на великій кількості потоків сервер, на якому розташований сайт, може не витримати навантаження та почати віддавати некоректний код відповіді сервера або тимчасово припинити відповідати на запити.
- Відсутність затримки між запитами → проміжок часу в мілісекундах, через який краулер звертається до сервера. Рекомендуємо встановлювати затримку під час сканування чутливих до навантаження серверів або захищених сайтів, щоб не перевантажувати сервер або імітувати поведінку користувача.
- Максимальний час очікування відповіді сервера – 30 000 мілісекунд. Якщо за цей час краулер не отримає відповідь сервера, у полі Код відповіді сервера з'явиться помилка Timeout, а сторінка буде вважатися битою.
- Включити JavaScript → функцію рендерингу за замовчуванням вимкнено. Вона дозволяє сканувати URL із виконанням JavaScript-коду. Це необхідно, коли частина контенту або весь контент сайту генерується з використанням JS-фреймворків та технології CSR (Client Side Rendering – виконання на стороні клієнта). За замовчуванням опція відключена, оскільки сайтів, що не використовують CSR технологію, переважна кількість.
- Сканування всіх піддоменів → дозволяє враховувати піддомени як частину сайту, що аналізується. Усі піддомени будуть проскановані, а посилання на них вважатимуться внутрішніми.
- Перевіряти зображення → необхідно для збору основних SEO-параметрів за картинками та пошуку помилок за ними. Посилання на зображення будуть додані до основної таблиці «Всі результати».
- Перевірити PDF → для збирання SEO-параметрів про файли цього формату.
- Перевіряти інші MIME-типи → архіви, RSS-фіди, відео та аудіо файли та ін.
1.2. Розширені налаштування
На цій вкладці за замовчуванням стоять такі параметри:
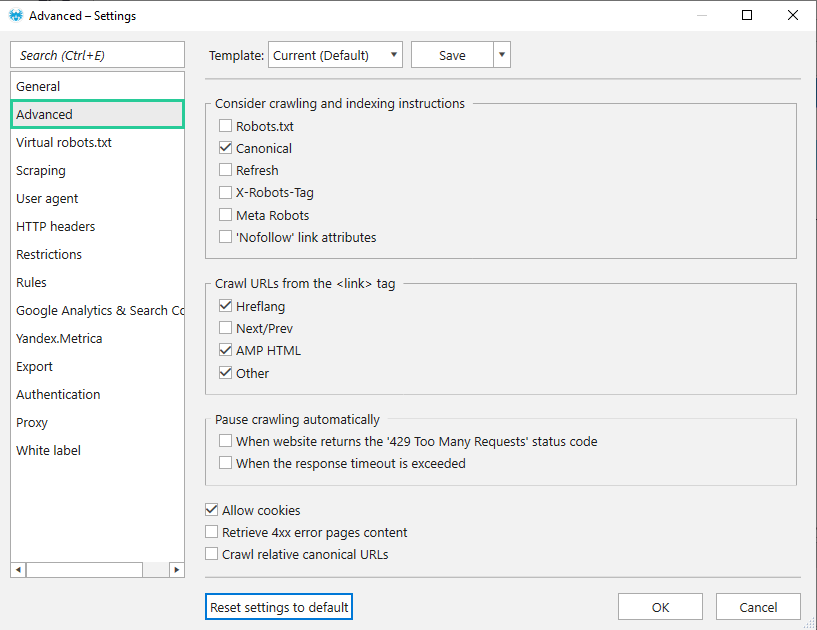
1. Відключено облік усіх інструкцій з індексації, крім Canonical. Так ви не ризикуєте упустити важливі сторінки із загального аналізу.
2. Увімкнено сканування посилань з тегу:
- Hreflang → a дозволяє переходити за посиланнями з атрибуту hreflang у тезі блоку або в заголовку HTTP «Link: rel=”alternate”» — це необхідно для перевірки коректності налаштування hreflang. Зверніть увагу, що Netpeak Spider скануватиме всі URL із hreflang (як внутрішні, так і зовнішні) незалежно від налаштування «Сканувати зовнішні посилання».
- AMP HTML → дозволяє знаходити та перевіряти сторінки, на яких впроваджено технологію AMP.
- Інші → для перевірки всіх URL з інших тегів у блоці та їх додавання до таблиці результатів.
3. Дозволено cookie-файли. Це зроблено для випадків, коли сайт не віддає інформацію при зверненні краулера без прийняття cookie-файлів. Cookie-файли дійсні лише в рамках однієї сесії.
1.3. User Agent
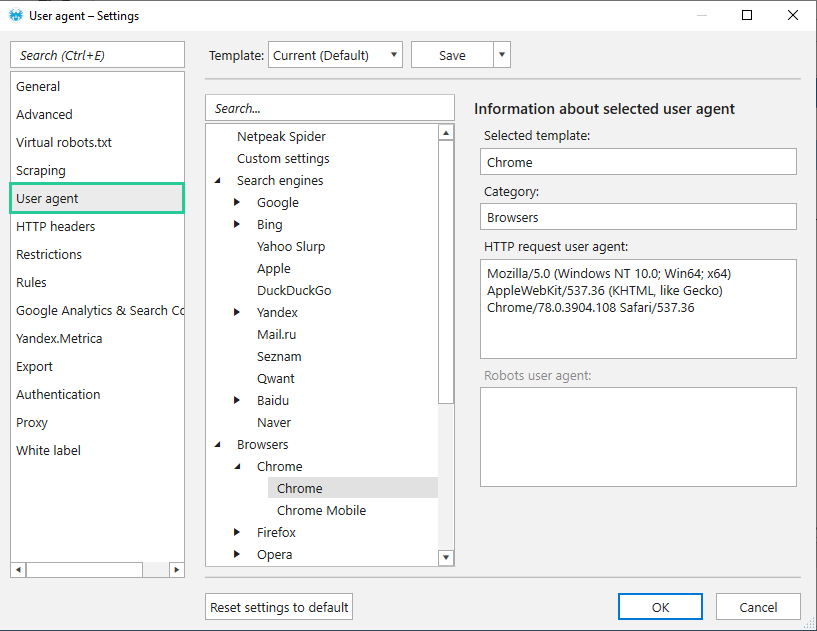
За замовчуванням Netpeak Spider сканує сайт, використовуючи Google Chrome як User Agent для повноцінного відображення результатів сканування, оскільки часто сторінки для нього відкриті та віддають коректний код відповіді сервера.
1.4 Налаштування обмежень
За замовчуванням кількість сторінок, що скануються, вкладеність і глибина сканування не обмежені.
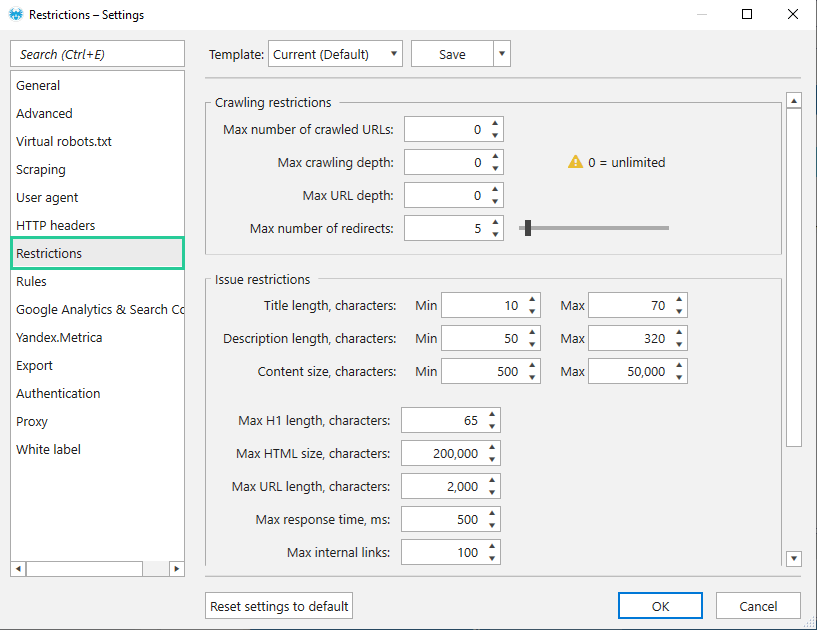
Максимальна кількість редиректів за замовчуванням – 5. У такому випадку програма переходитиме максимум за чотирма редиректами, а п'ятий — вважати помилкою. У полі «Обмеження помилок» ви можете самостійно задавати значення для деяких параметрів, щоб максимально гнучко налаштувати програму під ваші задачі. Це зроблено також через різні вимоги до певного параметра для кожної пошукової системи.
2. Сканування
2.1. Початок та хід сканування
Щоб швидко запустити сканування, додайте адресу сайту в полі «Початковий URL» і натисніть кнопку «Старт» на панелі керування.
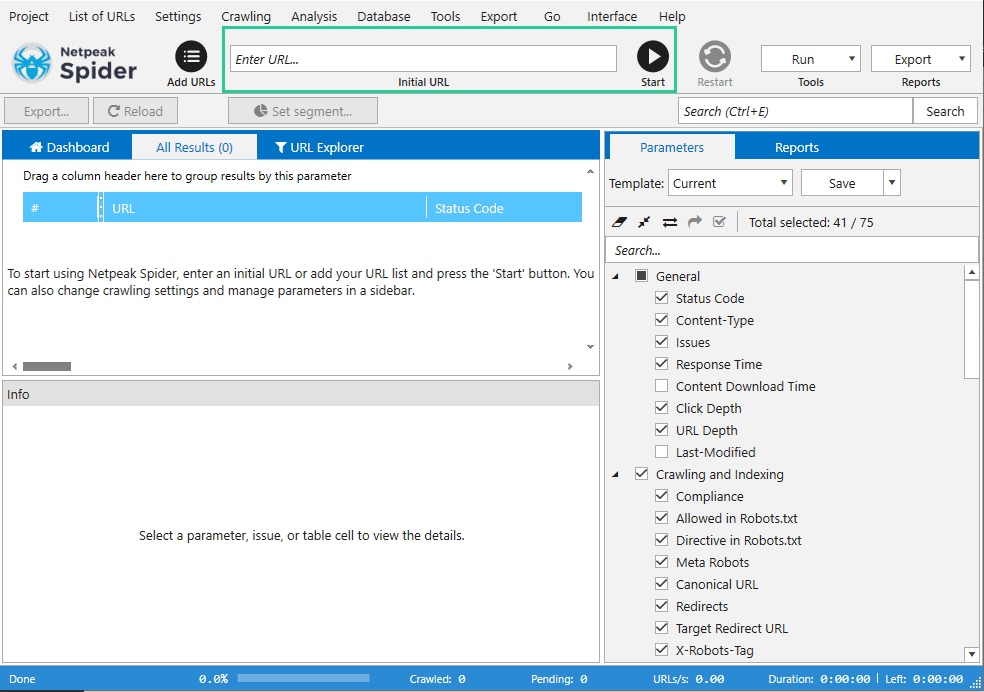
На вкладці Дашборд основної панелі відображається інформація про хід сканування та дані про налаштування.
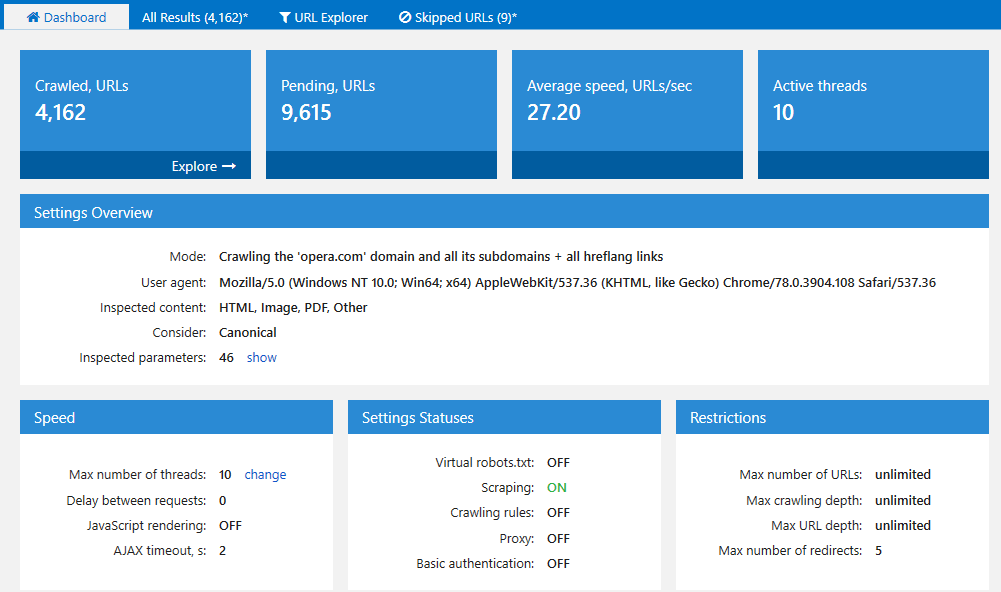
2.2. Зміна налаштувань під час сканування
У процесі сканування можна змінити кількість потоків. Зміни набудуть чинності відразу після натискання кнопки «OK».
Щоб змінити інші налаштування, необхідно призупинити сканування кнопкою "Пауза". Тоді зміни набудуть чинності після відновлення сканування (кнопка Старт) для непросканованих URL. Результати, отримані раніше, залишаться без змін.
Кнопка «Рестарт» на панелі керування очистить результати та запустить сканування сайту заново згідно нових налаштувань.
2.3. Пауза та відновлення сканування
Сканування можна зупинити на будь-якому етапі за допомогою кнопки "Пауза". Щоб продовжити сканування (наприклад, після зміни налаштувань), натисніть «Старт»: воно запуститься з місця, де зупинилося.
2.4. Аналіз даних
Після закінчення сканування (або при натисканні «Пауза») автоматично розпочнеться аналіз даних: дублікатів, вхідних посилань, ланцюжків Canonical та внутрішнього PageRank, підрахунок помилок згідно з конфігураціями параметрів із вкладки налаштувань «Обмеження». Також програма отримає дані із сервісів Google Search Console, Google Analytics. Після завершення сканування або зупинення проекту, буде вивантажено запити з Google Search Console, за якими ранжується кожна сторінка. Дані сервісу підтягнуться до програми, якщо перед скануванням відповідні параметри були включені на бічній панелі.
Аналіз можна переривати та відновлювати у будь-який момент → це робиться через меню «Аналіз».
3. Збереження проекту та експорт результатів

Після завершення або при зупинці сканування можна зберегти проект. Для цього оберіть «Зберегти... » ( Ctrl+S ) або «Швидке збереження» ( Ctrl+Shift+S ) на панелі керування у меню «Проект».
Збереження проекту через опцію «Зберегти... » дозволяє вказати директорію та самостійно вибрати ім'я файлу. При збереженні через "Швидке збереження" проект зберігається в дефолтну папку (зазвичай це робочий стіл) та з дефолтною назвою.
При необхідності, сканування можна продовжити пізніше або на іншому пристрої. Для цього:
1. Збережіть проект.
2. Відкрийте збережений проект за допомогою меню «Проект» → «Останні проекти» або «Відкрити» ( Ctrl+O ).
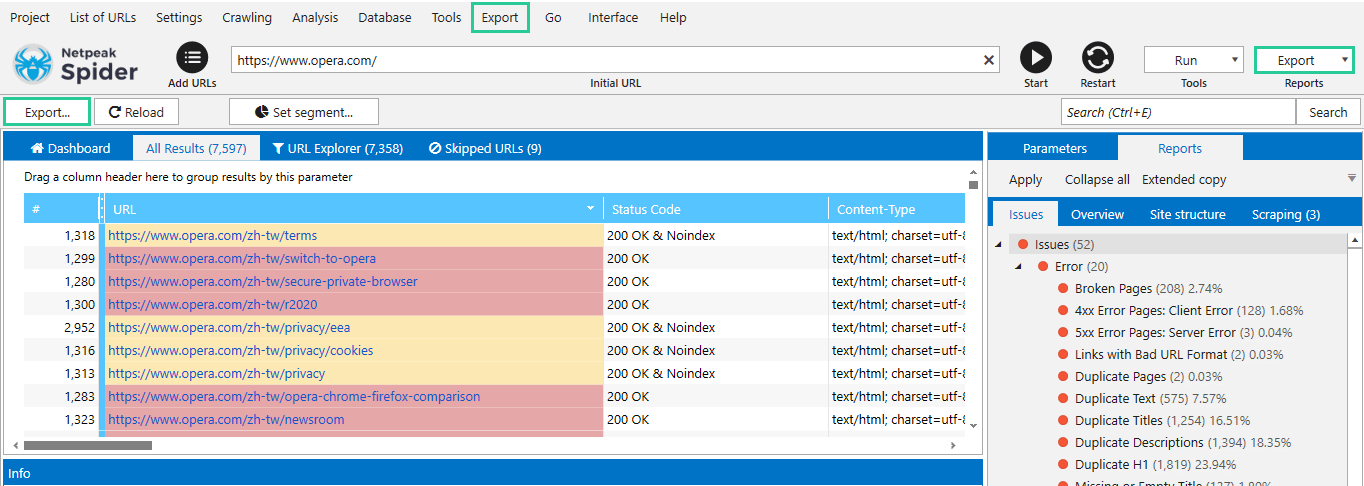
Алгоритм експорту всіх або частини отриманих результатів виглядає так:
- У меню «Експорт» на панелі керування або в головному меню виберіть потрібний шаблон звіту.
- Вивантажте результати поточної таблиці за допомогою кнопки «Експорт» зліва над таблицею результатів. Цей спосіб особливо зручний у разі застосованих фільтрів або роботи всередині таблиць модуля бази даних.
Ця стаття була корисною?
Чудово!
Дякуємо за відгук
Даруйте, що не вдалося допомогти вам
Дякуємо за відгук
Відгук надіслано
Дякуємо за допомогу! Ми докладемо всіх зусиль, щоби виправити статтю