
Read a detailed post about the update → 'Netpeak Spider 3.0: New SEO Hope'
Our team has released Netpeak Spider 3.0 with code-name ‘New SEO-hope’ and now you can watch a brief review of the new version or read the transcription. More than 300 different changes were implemented and you have probably read about them in our post. Now you can watch some of them in action. Use the buttons to go to the video part you’d like to watch on Youtube ;)
Comparison with Competitors and Previous Version
The first thing I wanna do is start crawling some website. I’m going to use www.opera.com because it has a pretty fast response time. So the crawling has started, settings are default. We’ll get back to it in a minute. Meanwhile, let’s go and check out what’s new in the new version of Netpeak Spider.
The main point of this update is that this tool was optimized for speed and working with giant websites. It means that if you have a website with more than 1 thousand pages, this should be a great upgrade to you. So let’s check comparison with competitors first and I’ll show you some of the updates.
The first table of comparison is about comparing new version to the previous one on a medium website which is 10 thousands page large. As you can see, a memory usage was three times less compared to the previous version, the disc space is pretty much the same, time to analyze 10K pages was reduced from 25 minutes to 3 minutes which is incredible. And changes really start showing on large websites. Here we have a table of comparison with time speed of crawling websites, and it took only 27 minutes to analyze 100K pages on the new version of the program vs. almost 14 hours on the previous version of the tool. And again, memory usage is four times less than in previous version. Big space is pretty much to save.
Now let’s see the comparison with actual competitors. On the medium websites we are analyzing 10K pages, and as you can see Netpeak Spider is using less memory than any other competitor. It’s time to analyze 10K pages is 3 minutes and it is the same as analyzing with memory mode in Screaming Frog.
Let’s go to large websites. Here differences are showing more. First, we have small usage of memory analyzing 100K pages and the fastest time again – 27 minutes vs. 44 minutes, the closest to the nearest competitor. Both tools were set to use default parameters. To be honest, it plays against Netpeak Spider 3.0 because by default it is checking PDF files and a lot of other stuff slowing down the process, and it still was faster. You can compare this tool to any other on your website yourself and see if any of these data is holding up. So we’re done with comparison and can state that Netpeak Spider is a very fast tool that doesn’t use any extra memory.
All this time it was crawling the opera.com on the background, and you can see that we’ve crawled 5.600 URLs already. It took us around 4 minutes, I believe, on default settings. Not fast as it’s listed here, but it depends on the website and the computer you are working with.
Let’s move to the updates of the 3.0. We’ve already gone with optimized RAM usage and up to 30 times faster crawling, especially when it comes to the large websites.
Option to Resume Crawling After Opening the Project
Next we have option to resume crawling after opening the project. As you can see we’ve passed 6.8K pages now. You can pause a project at any time. I can decide whether I want to analyze the link weight distribution of the website or not. Let’s keep it to see how long it takes. And after you’ve paused the project, you can either close your laptop, go home and then come to office, and resume crawling again. Or you can actually go and save your project, transfer it to another machine or open on the same computer.
And that will allow you to resume crawling from the same spot you’ve stopped earlier.
You can save the project, name it however you like, for example, ‘Test project’. And I can clear all the results. So let’s see, I can open it. And we’re back to the 6K pages. And if I hit ‘Start’, we’ll resume from the same spot. If you want to rescan, just hit ‘Restart’. So as you can see, we are continuing from 6K pages analyzed. Again you can transfer this project to the other machine where you have Netpeak Spider installed and resume crawling from that place.
Deleting and Recrawling URLs from the Report
Also, you can remove URLs from reports or rescan the list of URLs. With these two options you can basically work with URLs in your reports. For example, you are checking some website and you suddenly realised that you don’t want to analyze some of the URLs here, for instance blog.opera.com. You can go ahead, select these URLs, right-click on them and delete them. Now you’ve removed these URLs from your main table. You will not see any issues related to these pages. This is a useful feature in case you are working with large websites, and you know that part of the website hasn’t been touched in years and there is nothing you are going to do with it yet, so you can as well ignore and remove it from reports to keep them clean.
And similarly to deleting, recrawling the URLs means that, for example, you are working on a website and you’ve found number of pages with missing or empty H1 heading. You take these URLs with missing or empty H1 headings and create a task for team of copywriters or content team on your project to come up with unique H1 headings for each page. You save your project and go home. A week later they tell you that they’re done with H1 headings, so you can open your project – missing or empty H1 headings – where you will have these reports, and you can select all of the URLs here in the current table and rescan the table. Or select some URLs and rescan these. It really comes in handy, if you need to check changes in these URLs without having to recrawl all website again.
Changing Parameters During Crawling
This new feature means that if you have your project put on pause like I do here, and you see that you have, again, a lot of pages with missing or empty H1 headings but you actually don’t care about that for whatever reason, you can go to parameters and decide if you want to check them or not. The information about parameters you have just disabled will disappeared from the reports, but if you enable them back during crawling, they will be shown for the pages that were analyzed. This feature can be very handy in saving your RAM during crawling.
Data Segmentation
This is a really pretty big feature and a cool one. It helps you analyze your website more efficiently. So you have dashboard with a lot of information. The thing about segmentation is that you can use anything in it as a segment.
For example, you have a list of compliant and non-compliant URLs. This is also a new feature in Netpeak Spider and I’ll tell you about it right now. It notes whether URL is compliant or not. Compliant URL means that it is not closed from indexing, and it basically fits all the necessary parameters for it to be indexed and ranked by Google.
So you can click on the compliant URLs and then use them as a segment. As you can see number of errors decreased because now Netpeak Spider is working only with URLs that are compliant. So if you had issues on any pages that were not supposed to be indexed, they were removed from the list here.
And similarly you can work with errors. You can go and click on duplicate titles and use this error as a segment – now you have compliant URLs with duplicate titles. And when you switch to the site structure, you can see where exactly you have these compliant URLs with duplicate titles.
It helps, again, with working on large websites. For example, you can find that your blog section has a lot of issues with titles, so you can focus on that section of the website, fix it first, and drastically improve the quality of the whole website by focusing only on the one segment. So you set the segments and now go back to normal view of your project.
Dashboard
We have dashboards (information about crawling process and diagrams after it’s complete). You’ve just seen it in action. It basically means that if you have a dashboard with two states. As it crawls, you can see how many URLs have been crawled, how many URLs are left to crawl, the average speed and active threads, and you see what settings are you using.
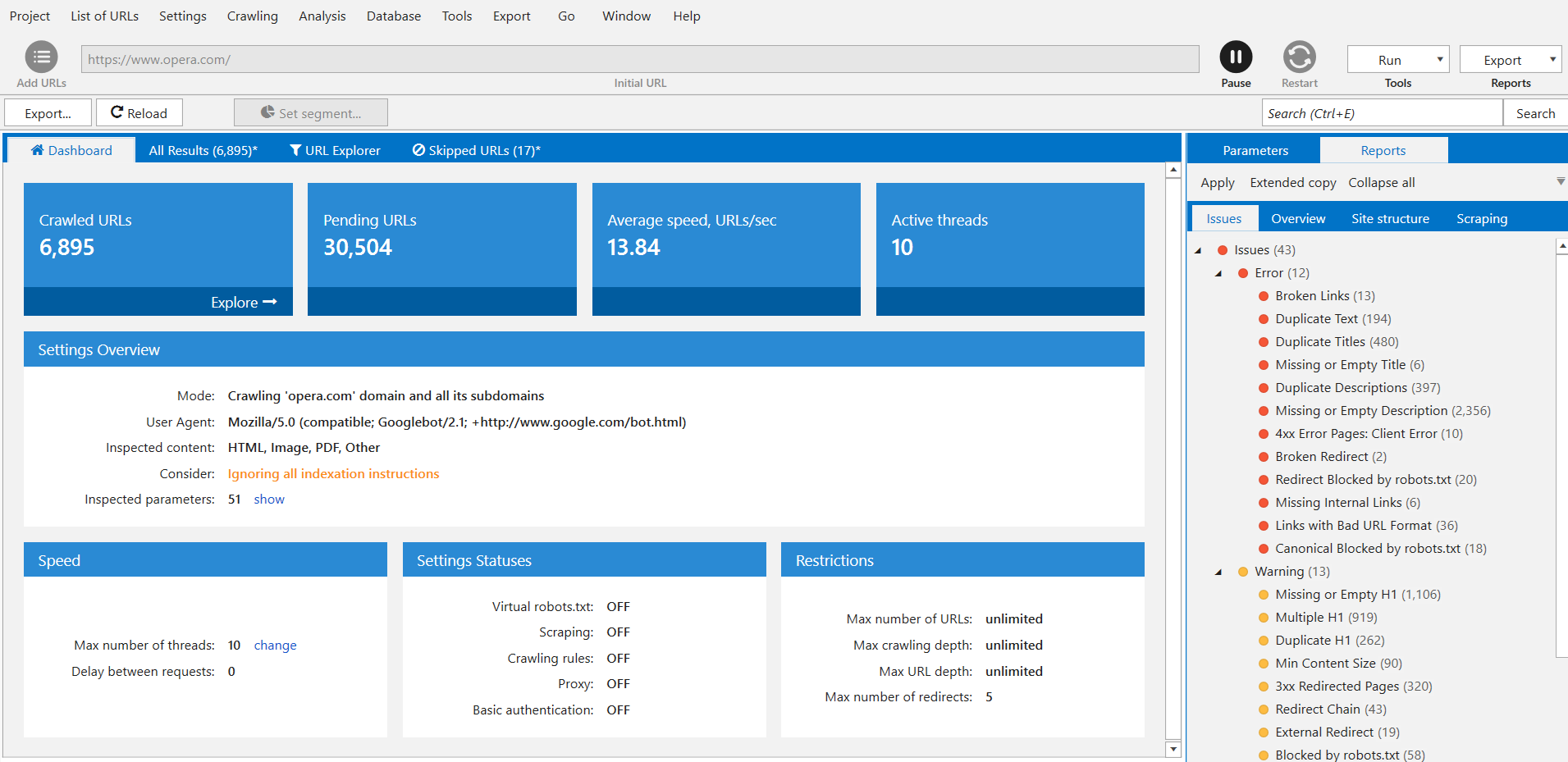
It’s a very important update because sometimes you can launch project and, for example, mistakenly enable consideration of robots.txt file. And you want to check all of the website, but you have recently made some updates in robots.txt and most of your website is disallowed now. Netpeak Spider will skip the pages disallowed in robots.txt and you will not get any results for those. And now you can check your indexation instructions.
You can also see here what user agent and crawling mode you are using, so just basically you can double-check your own preferences again, settings for virtual robots.txt, scraping. We can see now that we are actually crawling opera.com website with these settings and everything seems to be fine. And after you’ve stopped or paused the project, you’ll get the dashboard with results.
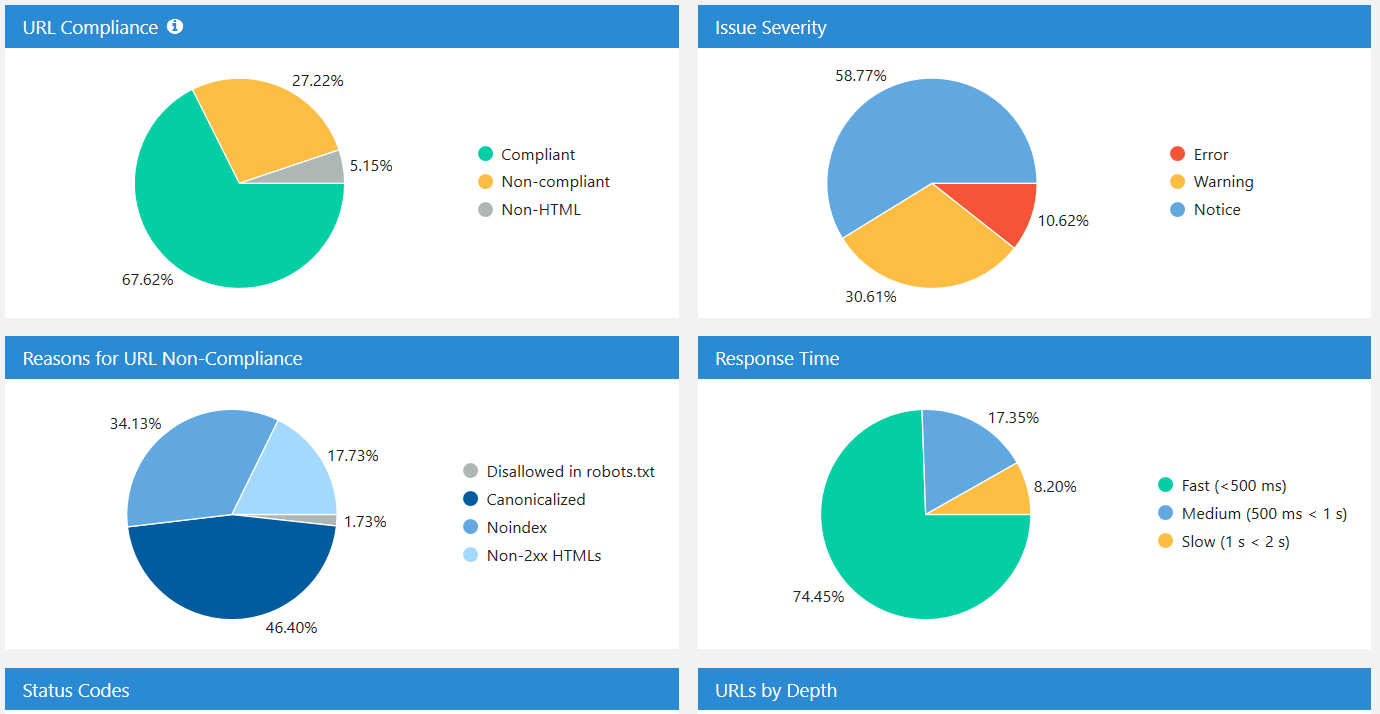
Here you can find the break down by your response time, how many pages you have with errors, etc.
Exporting 10+ New Reports and 60+ Issue Reports in Two Clicks
Now actions you have to go through to export anything have been minimized to just a few. You have to click on the special export button and you can export all available reports at once and get everything for opera.com or just export any sort of report you are looking for.
Like if you are looking for broken links, you can export current table and get just information about broken links.
Another upgrade to exporting feature is that now if you export information about broken links, you’ll get the report looks like this.
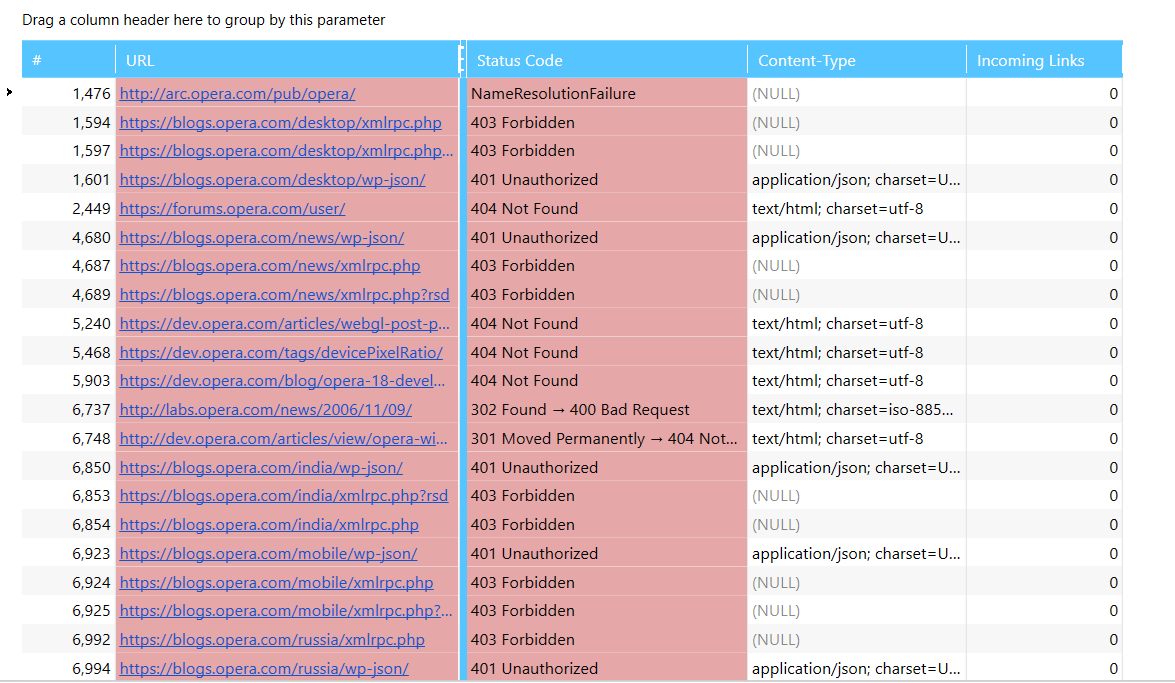
In previous version you would have got every issue for the page. So if this page has more issues than three and you’ll get all of them listed in report you export. You can still enable export all the data available on selected pages, but it is easier to work with reports separately.
Rebuilt Tools ‘Internal PageRank Calculation’, ‘XML Sitemap Validator’, ‘Source Code and HTTP Header Analysis’, and ‘Sitemap Generator’
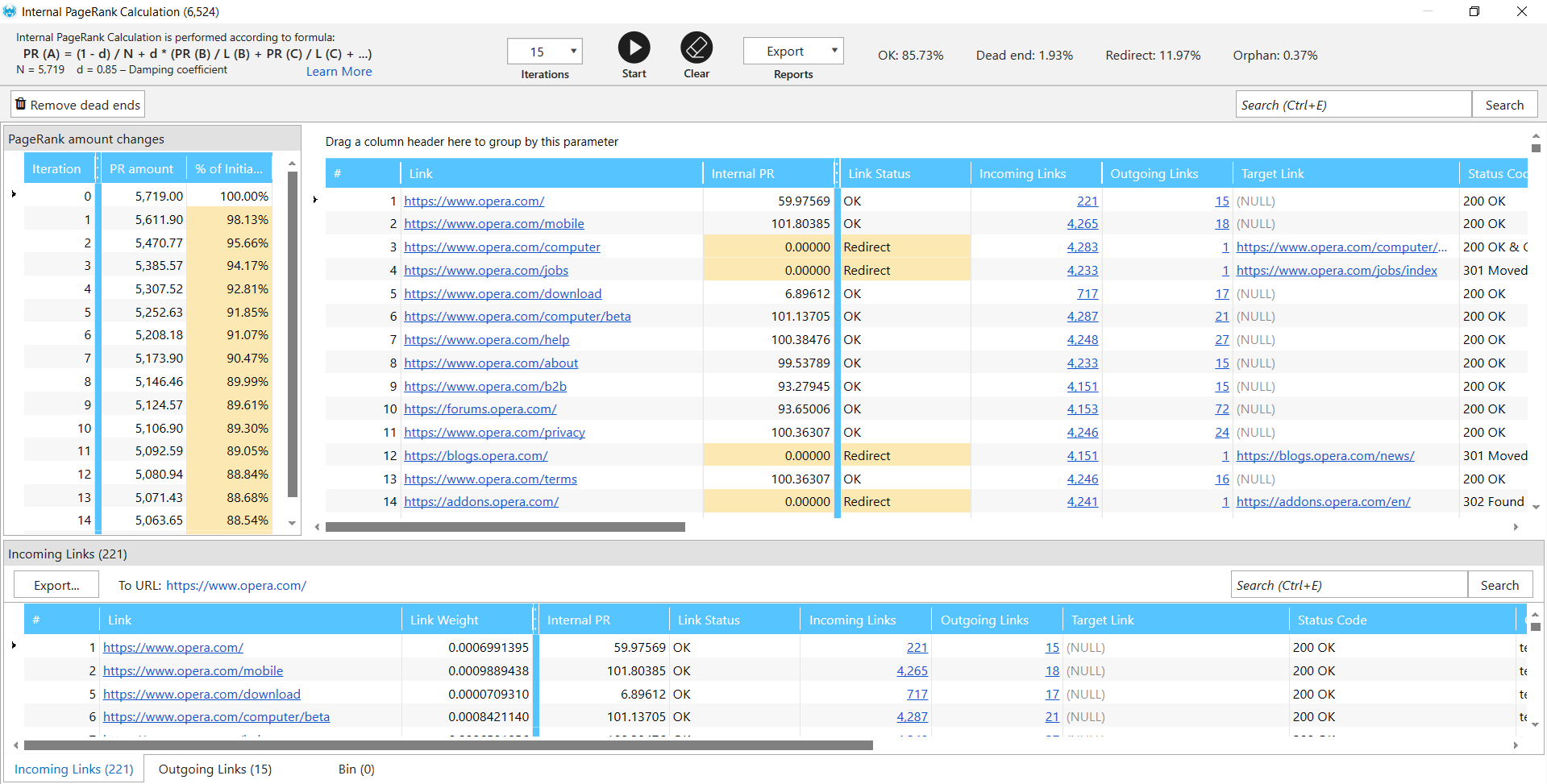
So internal PageRank is a tool which shows you how link weight or link equity is distributed throughout your website. It shows sufficient dead ends when some page has incoming links but no outgoing links, it means that it doesn’t link to any other page and it doesn’t pass any link weight. It breaks your link weight distribution within the website. So this tool shows you what is the authority of every page on your website. It’s very useful for reworking your site structure and internal linking on your website. In this version we’ve changed the formula a little to make it more accurate.
Now about some changes to XML sitemap validator. It now analyzes up to 34 possible errors with sitemap, and you also can use Netpeak Spider to scrape the links from sitemaps or ping the sitemap to the search engine to notify it about any changes.
The source code and HTTP header analysis tool has been reworked. Now it can show you not only the source code of the page, but also you can see just the text on the page.
Sitemap generator has also been improved. It now works only with compliant URLs. So if your page is disallowed in robots.txt, it has canonical to different page or noindex, it will not be included in the sitemap. So this is a very pretty cool change, in my opinion.
Custom templates for settings, filters / segments, and parameters
So everything we work with here is customizable, as you have probably seen. For example, you have your parameters here which you want to work with, then you have settings (bunch of them), number of threads (let’s give it to 10, not to overloading website). When you change anything, you have an option to save it as template. And then when you want to work with the website with the same settings, you can go ahead and open your template with your selected parameters and your settings and work with that.
Virtual robots.txt
This feature allows you to test robots.txt settings. You just go to the settings, open virtual robots.txt, enable it, paste whatever you like. For example, you want to see what will happen, if you disallow every bot on your website. You can resume crawling and enable your robots.txt via virtual robots.txt in Netpeak Spider. At first glance, there are no changes in general. To check if it’s working, track the number of non-compliant URLs changing. It increases, so this update is alive.
Combining Crawling Modes
You can combine crawling modes into one. You can crawl your website as we do right now and add another one to check URLs separately. Right now with this update you can check the website and then add the list of URLs and resume crawling. First Netpeak Spider will check website itself, and then go on to the URLs you’ve just uploaded. You cannot combine two websites in a project but you can combine any website with any list of URLs.
Skipped URLs
List of URLs skipped by crawler shows you which URLs are not analyzed by Netpeak Spider while checking a website. It usually happens because you have decided not to check them. For example, you’ve gone to settings and set up a rule to exclude any URL that contains ‘blog’ word. So if you have this setting while analyzing website and Netpeak Spider crawls URL with word ‘blog’ in the address, this URL will not be analyzed and you’ll see it here.

Quick Search in Tables
Another update is a quick search in tables. It means that you can perform a quick search inside your tables. For example, you have a list of broken links here and want to see if there are any pages from the blog here. So I just use this quick search feature and have a list of pages from blog – the ones that contain broken links or that actually are broken links. This is how the quick search works. It works in every table you have in Netpeak Spider.
Delaying Comprehensive Data Analysis
PageRank, for example, is now calculated after the crawling is complete or after you hit pause.
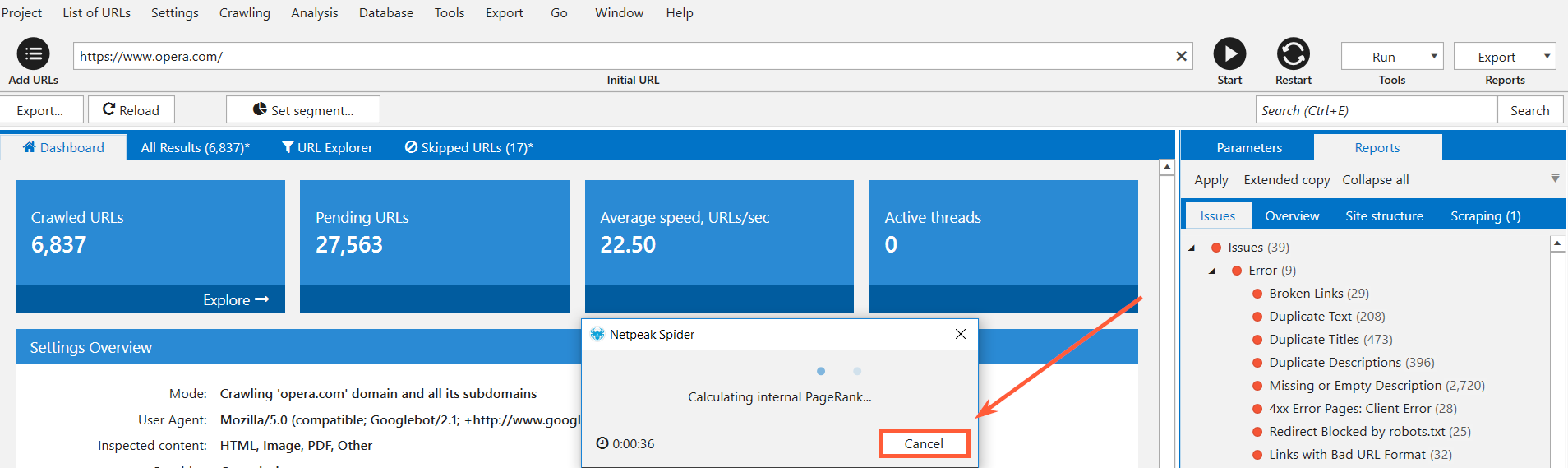
Moving a little bit of calculation to the end of the crawling has a huge effect on crawler speed itself.
Monitoring Memory Limit
Also, you have monitoring memory limit for data integrity. Netpeak Spider is now tracking the amount of memory available for running website crawling. It will not start if you don’t have sufficient memory, you will see a warning and will be able to resume crawling on another machine with more memory on it.
And there are hundreds of other improvements you can learn about from this blog post and from Netpeak Software blog in general where we show use cases with Netpeak Spider and what’s new with it. And check out Netpeak Spider 3.0, a new version which is probably the fastest crawler available at the moment with tons of cool features :)
Thank you guys for watching, see you next time. Bye!
Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article