
Even though we call this Netpeak Spider update 'minor release', it includes more than 30 improvements of functionality and usability. Let's dive into new features! ;)
- Site Structure Report
- New Report on Redirects
- Scraping Summary in Single File
- Exporting Pending URLs
- New Report Export Menu
- Custom Table Configuration
- Expected Crawling Duration
- Synchronizing Tables with Parameters
- 'Filter by Value’ Option
- Other Changes
- In a Nutshell
To export various reports, you need to subscribe to the Netpeak Spider Standard plan, where you can also analyze 80+ SEO parameters, scrape websites, segment and filter data, save projects, and much more. If you are not familiar with our tools yet, after signup, you’ll have the opportunity to give a try to all paid features immediately.
Check out the plans, subscribe to the most suitable for you, and get inspiring insights!
1. Site Structure Report
1.1. What Is Site Structure Report Used for?
This report allows you to comprehensively analyze your or your competitor's website in the context of the segments in the URL structure, and, by the way, it's quite fast. Understanding the website structure helps to discover insights → why a certain project successfully ranks in the search engine results. You can always copy successful solutions and / or improve them to achieve better results.
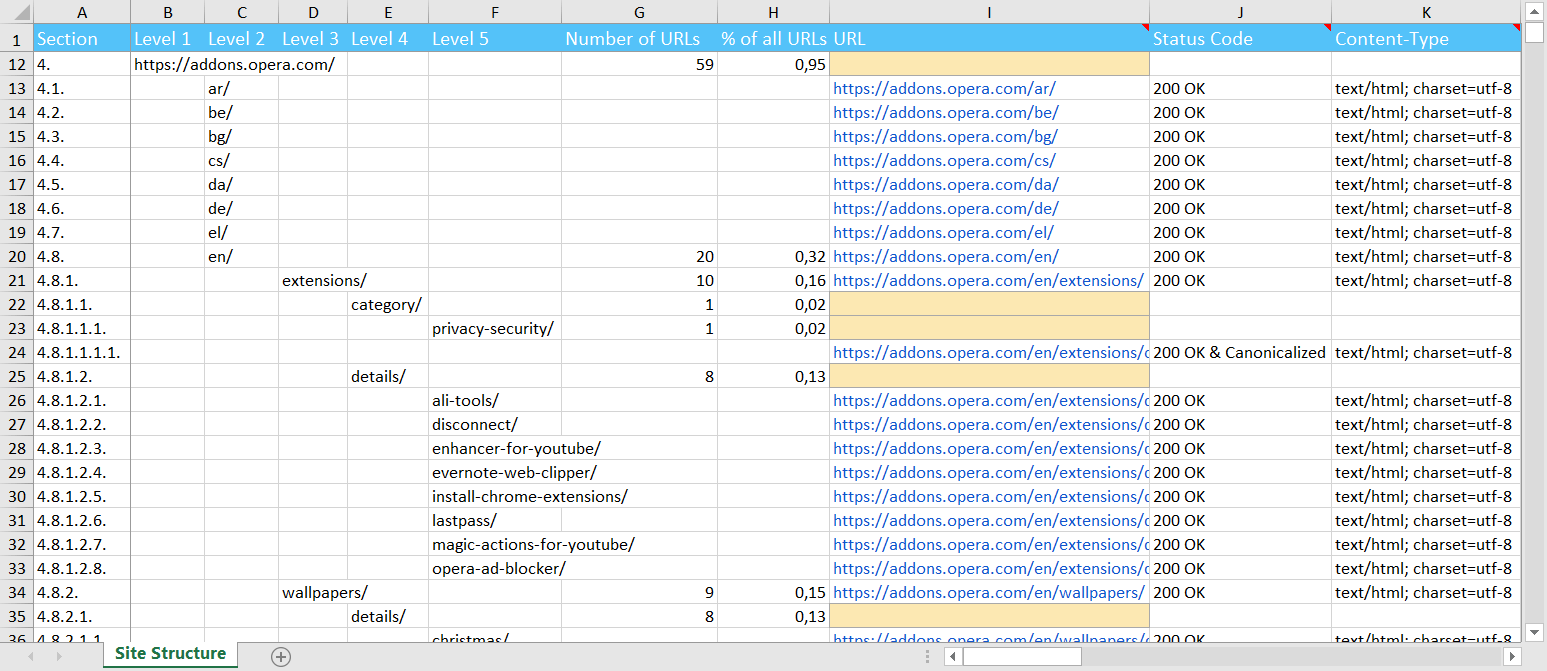
1.2. Peculiarities and Advantages
- All parameters that were selected (and analyzed) in a sidebar in the 'Parameters' tab will be included in the report. Pay attention to the new function 'Sync the table with selected parameters' (I will talk about it a little later), because it reveals the full potential of this report.
- We've implemented the 'Section' column. It is a counterpart to the subitems in the documents and makes it easy to sort the structure and also quickly determine the number and uniqueness of segments in URL. Also we've added this column to the extended copy feature, which is available in the 'Site Structure' tab in a sidebar with reports.
- Like all other reports, the site structure can be exported in .XLSX or .CSV format.
- Pages with the 'Redirect' type are excluded from this report, so you will see only final URLs (you are probably not very upset).
- If the section does not have the main page, then the corresponding cell in the 'URL' column is marked in yellow. Perhaps this is not a critical issue, but it will make you think about the correctness of your URL structure.
- All sections and GET-parameters are URL encoded (for example, https://site.com/%D0%BF%D1%80%D0%B8%D0%BC%D0%B5%D1%80%0A), while in the 'URL' column you will always see a user-friendly page address.
- Site structure report is based on URL segments (the number of slashes in the page address). Not all sites are designed in such a way that you can accurately determine the category of a product or an article by the URL. In this case, simple exporting of all pages with the depth level (the number of clicks from the initial page to the analyzed one) can help.
Tip: Excel (or Google Spreadsheets) has a Ctrl + ↓ shortcut. It allows you to move to the next data cell. It's very convenient when you need to view all sections at the same depth level.
2. New Report on Redirects
2.1. What Is 'Redirects: Incoming Links and Final URLs' Report Used for?
This is one of the most requested features from our clients because in order to fix redirect issues on the website, you need to know clearly:
- which page includes the link with the redirect
- where the link initially leads
- and the final page address of the redirection
We've implemented this report and added other useful data to it, so now you can send it to developers or content managers with a task to fix unnecessary redirects. Redirects themselves are not a critical problem, however, if you find redirects while crawling your site, then it is a pretty clear sign that server capacity is wasted. It means that you should put direct links to the final pages within your site.
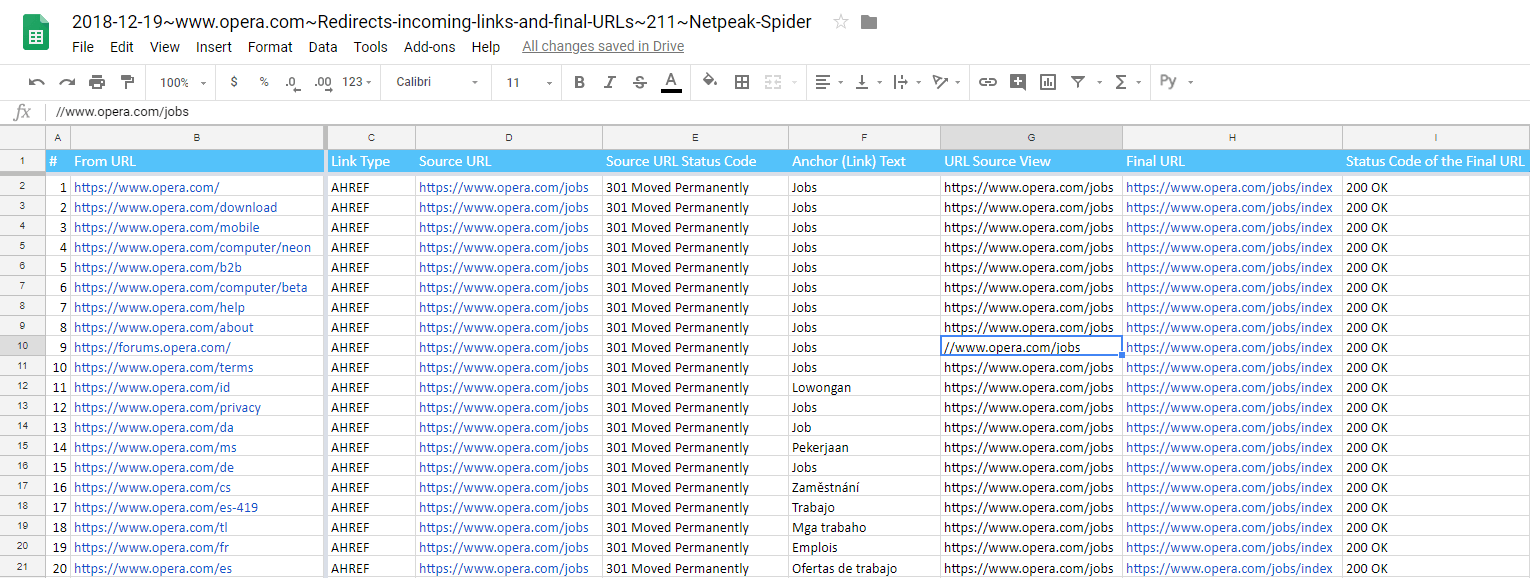
2.2. Peculiarities and Advantages
Redirect chains are not displayed in this report because you can find them in another report 'Redirect Chains' (surprising coincidence, isn't it?). The main point of the new report is to remove unnecessary internal redirects, that's why we've implemented the following columns:
- From URL → this is the page with a link leading to a redirect.
- Link Type → this is our common indicator that helps figure out whether is an ordinary link (AHREF) or, for example, it's a link from an image (IMG AHREF).
- Source URL → the page address that redirects to another page, so this is the initial URL which contains a redirect.
- Source URL Status Code → for better understanding which redirect is set (e.g., 301, 302).
- Anchor (Link) Text → for clear understanding of the link purpose and where it should lead.
- URL Source View → it's our unique feature. The link in the source code may look completely different, so that's why you can see its original form in this column. You can just copy the value and find it in the source code of the page.
- Final URL → if the redirect leads to the correct page (and this still needs to be double-checked), then the source URL above must be replaced with the value in this column.
- Status Code of the Final URL → similarly, for a better understanding of whether a redirect is correct (after all, a redirect can lead to a page with the 4xx status code).
Keep in mind: if Netpeak Spider found a redirect, but did not find any incoming links to it (for example, you just uploaded your URL list, and did not crawl the site), then a new report cannot be built. It seems obvious, but 'forewarned is forearmed'! :)
3. Scraping Summary in Single File
3.1. What Is 'Scraping Summary in Single File (XL)' Report Used for?
Until now, you could export the report for each scraping condition separately. All results in such reports were shown vertically. For example, you have 3 different scraping values, so each value was in a specific line, and the URL was duplicated in its column. Now such export is called 'Data for scraping conditions in separate files (XL)' (I will explain what XL means a little bit later). In certain cases only such export is appropriate, and it looks like this:
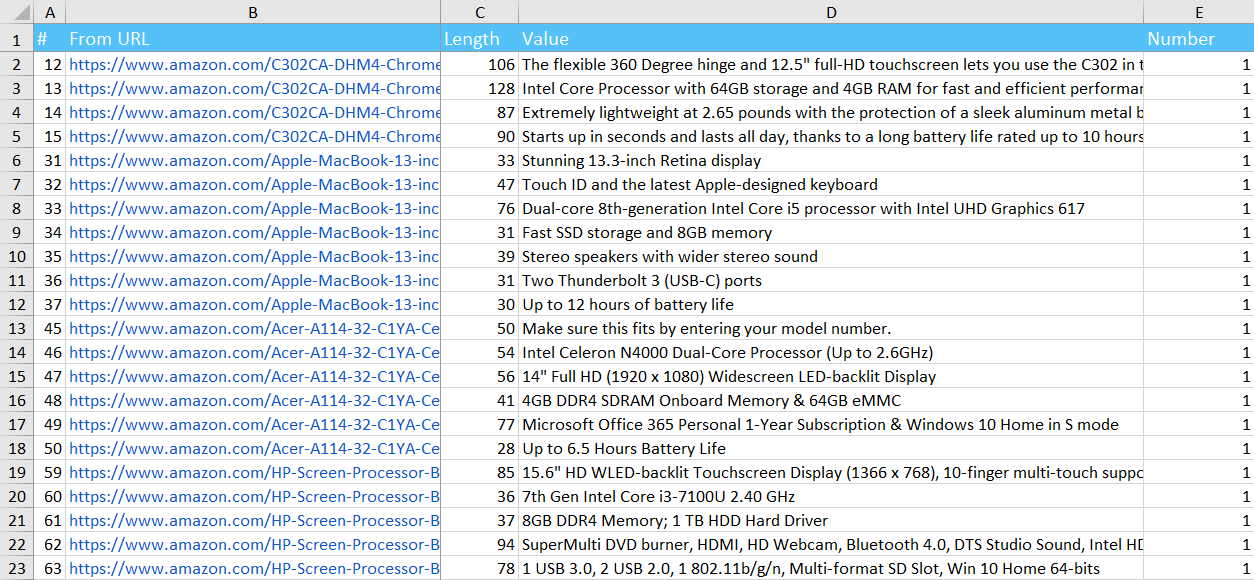
However, we've received requests from users that in some cases they need another export. Therefore, meet the new 'Scraping summary in single file (XL)' report. So you can see a horizontal data layout with unique URLs in this report. Thus, as on the example above, if 3 scraping values were found on one page, this report will contain one row with the URL, and all scraping results are given in different columns. It looks like this:

The number of scraping cases is nearing infinity, so you can decide which report type is more suitable for your purposes and use it. We aim to provide flexibility and limitless opportunities!
3.2. Peculiarities and Advantages
- 'Server Response Code' and 'Content Type' are also added to the report next to each URL. Now, this report is similar to the data in the 'All Results' table, but you'll see scraping data instead of parameters.
- Similarly, you can export the new report in the .XLSX or .CSV format, but each of the options has its nuances.
- In the .XLSX format you'll see notes in the header of each column, they indicate scraping conditions. However, .XLSX has a limit of 16,384 columns and if the limit is reached, remaining results will not be shown. Please note: the limit is also set by the programs / services you use to open the report (for example, when opening the .XLSX file in OpenOffice / LibreOffice, the limit will be 1024 columns, and in Google Spreadsheets – only 256).
- If you export the report in .CSV format, there is no limit on the number of columns.
- Note: filtering by only HTML files that return the 2xx status code has been removed. So now you can, for example, check the same list of URLs, keep history in Excel / Google Spreadsheets and not worry about wrong table formatting when one of the URLs stops returning 2xx HTML.
- The new report is perfectly suited for exporting, for example, product pages, where one URL includes the product name, its price, a link to the image, and all its characteristics.
4. Exporting Pending URLs
4.1. What Is 'Pending URLs' Report Used for?
I think that no webmaster can say for sure how many pages his website consists of (especially if we talk about medium and large Ecommerce sites). There are always some dynamic pages (such as sorting, filtering, grouping) that make the exact calculation quite challenging. One of the Netpeak Spider tasks is to figure out how many pages you or your competitors have and what they are.
However, if the site is large, then crawling all the parameters for all pages becomes a longstanding and difficult task. At this moment a new 'Pending URLs' report comes to the rescue. It allows exporting all the links that Netpeak Spider found, but didn't crawl. And there are no limits to boot :)

4.2. Peculiarities and Advantages
- This is uncommon feature. I've checked a large number of tools, and not all of them allow their customers to know when the crawling is about to end and you can see the report.
- The report consists of three columns: '#', 'URL', and 'Depth' that shows the level at which the corresponding link is reachable, and thus its priority in the crawling queue. The smaller the click length, the faster a URL will be crawled.
- The report also includes those links that have already been added to the results table but have not been crawled yet. Depth of such URLs = 0.
- Please note: before starting crawling, you can configure specific rules for crawling. If you have done this, then these settings will be taken into account in the exported report. Segmentation will not affect the report any way, as there was no segmentation when drawing up a queue.
- Even though the maximum pending limit in the status bar is 1,000,000 URLs, you can export this report with no limits.
5. New Report Export Menu
Time has come to describe how we've changed report export menu and what the mysterious abbreviation XL means. Have a comfortable seat and let's keep going ;)
Now report export menu looks like this:
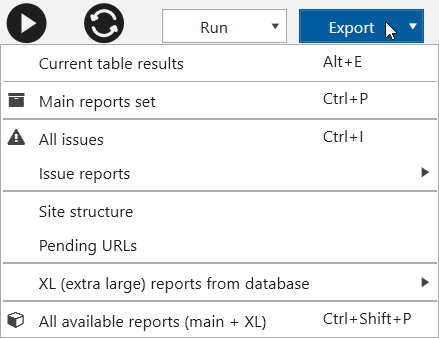
New grouping includes the following items:
- Current table results → it's a common item, you can open it using Alt+E keyboard shortcut.
- Main reports set → it's a bulk export including 'All issues', 'All results', 'Site structure', 'Scraping summary in single file (XL)' (if you set scraping) and 'All unique URLs & anchors (XL)' reports. Keyboard shortcut: Ctrl+P.
- All issues → it's also a bulk export including all reports from the 'Issue reports' group. Please note that only detected issues will be exported, so you will not get an empty file with 4xx issues (as some crawlers do). Keyboard shortcut: Ctrl+I.
- Issue reports → here are 'All issues from sidebar' (new report that exports all issues you see on 'Issue' tab in a sidebar) and the list of separate useful reports with issues.
- Site structure → read paragraph 1.
- Pending URLs → read paragraph 4.
- XL (extra large) reports from database → all these reports have XL mark that means 'Extra Large'. So this reports potentially can be very heavy. This group includes scraping data (summary and separate reports for each scraping condition) and link reports (internal, external, and, additionally, unique URLs and anchors).
- All available reports (main + XL) → it's the heaviest type of bulk export because it includes all prepared reports except 'Current table results'. Keyboard shortcut: Ctrl+Shift+P.
I also want to remind you about two cool reports that can only be exported (you can't see them in the program interface):
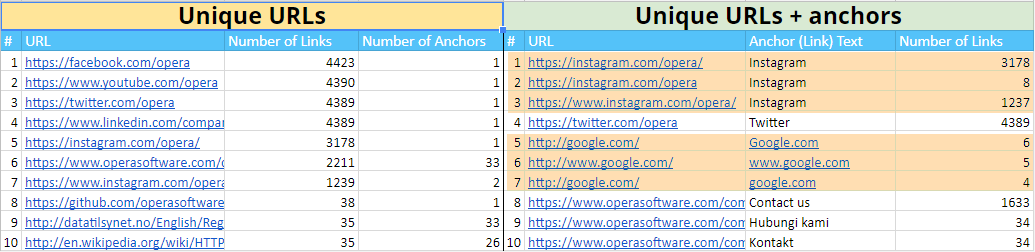
- Unique URLs — here you can see all unique links on your site (internal and external in separate files), their number, and even the number of unique anchors that are used for these links. It is handy, for example, to understand which external sites you refer to or how many different anchors are used for some internal page of the analyzed site. You can find this report in the new structure in the 'Massive reports from the database (XL)' group.
- Unique anchors — there is no URL limit; on the contrary, the data is grouped by anchors, and the number of links with such anchor is exported. If in the previous report you could only see a number of unique anchors on a particular page, then in this report you can look at the anchors themselves and even their number. It's useful for more in-depth analysis of the site internal linking and understanding whether there are enough anchors used for links to certain groups of pages.
6. Custom Table Configuration
Folks, I really love this feature! It gives an opportunity for customization, so you'll be able to play with tables as you like :) Also, it allows to customize settings of all tables with saving even after program restart.
6.1. What Exactly You Can Configure
- Column width
- Column position (relative to each other)
- Data sorting in the columns (without sorting, sorting descending or ascending)
- Results grouping (when you move the column heading to the top of the table)
- Fixed columns (by default # and URL)
6.2. Where You Can Configure All These Things
In a nutshell, in all program tables. In details:
- In the main panel tables (separately): 'All results', 'URL Explorer', and 'Skipped URLs' (you can see this table only if you have such URLs: they are usually skipped because of indexing instructions or crawling rules).
- In the 'Info' panel tables (bottom of the main panel).
- In tables opened in a sidebar: in the 'Issues' section (pay attention that each issue can be set separately), and in the 'Overview', 'Site structure', and 'Scraping' sections. When you open them, you'll see a table with filtered results, that's why you can customize only this table.
- In all tables of the 'Database' module (links, images, headings, redirects, Canonical, and issues) including 'Scraping overview'.
- In tables inside of each tool: 'Source code and HTTP headers analysis', 'Internal PageRank calculation', and 'XML Sitemap validator'.
6.3. How to Reset Settings
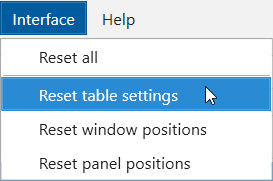
- Reset settings in all tables: the main menu 'Interface' → 'Reset table settings'.
- Reset settings only in the current table: 'Reload' button on the control panel. Please note that this function works only for the main panel tabs and does not work during the crawling (clicking on the 'Reload' button during the crawling simply loads newly crawled URLs into the table).
I also want to remind you that in addition to table settings customization, the program allows you to customize windows positions (their width, height, and screen position), as well as panels positions (also dimensions, but relative to other blocks and panels). And all settings will be saved after leaving the program. If you've accidentally set up a table in such a way that it became inconvenient to work, then you can always reset the settings in the same menu (but be careful, settings cannot be restored after the reset).
7. Expected Crawling Duration
I bet you wondered how long it would take to crawl a certain site. It's easy to answer when you know the exact number of pages on the site and the average server response time. However, you hardly know these variables even if this is your website because something is constantly changing from release to release (new pages, articles, product range updates, and much more).
In this case, the new Netpeak Spider comes to the rescue. Given the average crawling speed and the number of pages in queue, it calculates the expected duration of crawling and shows it in the status bar:

To improve the accuracy of calculations, we have expanded the crawl queue by 10 times – from 100 thousand to 1 million unique URLs. However, be careful: this is a floating value that directly depends on the crawling speed which (strongly) depends on the server response time and (slightly) on the performance of your computer.
8. Synchronizing Tables with Parameters
A very important button from Netpeak Checker has finally made its way to the new release of Netpeak Spider. It allows you to mark the parameters you need in a sidebar and synchronize the table with these parameters:
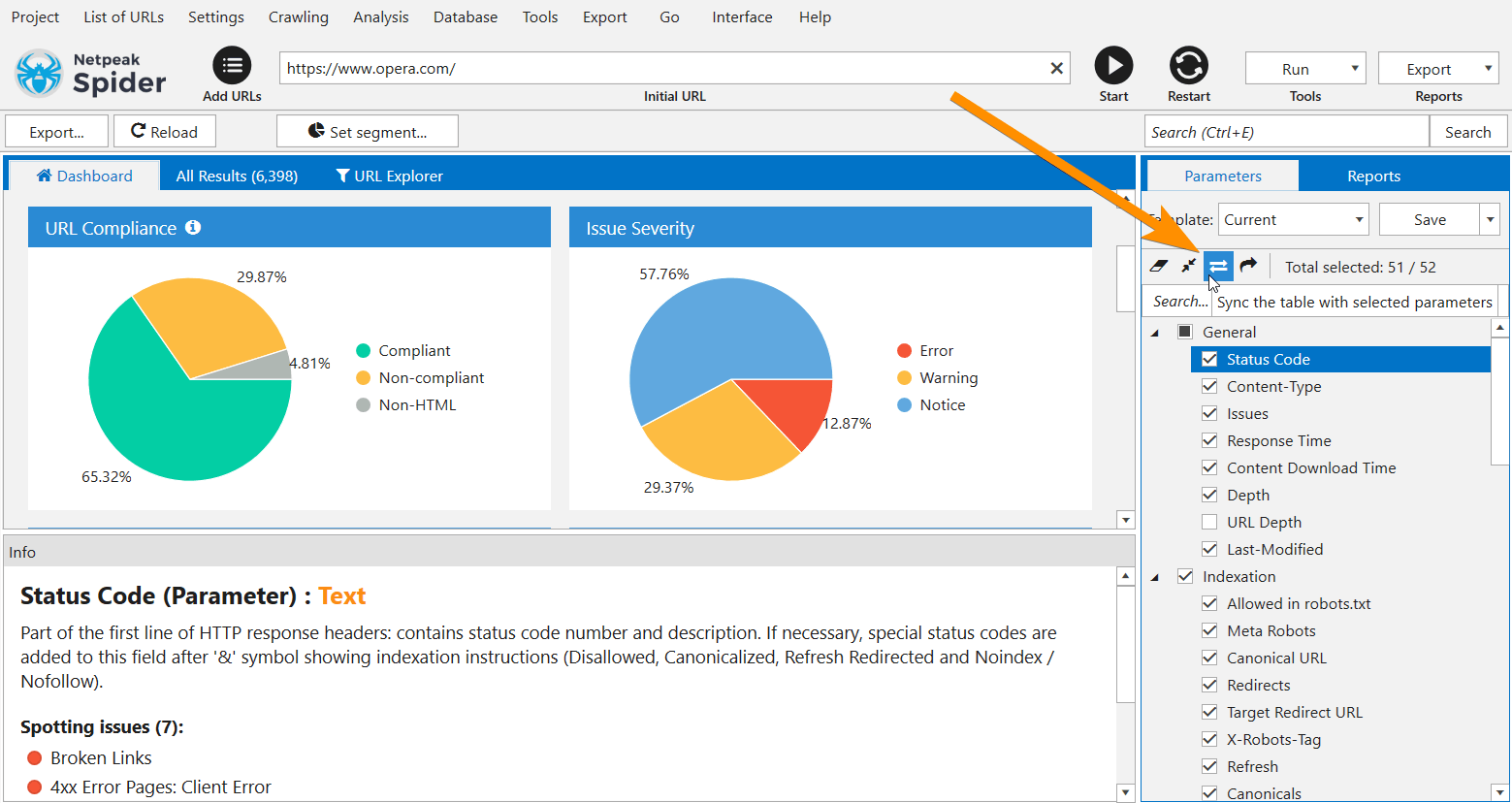
Once our user asked me: 'How can I quickly see and export a report consisting only of URL and Title?'. I was a little confused: though Netpeak Spider has very advanced customization, but this case was not covered. Now you can turn off all unnecessary parameters in a sidebar, click on the 'Sync the table with selected parameters' button and then:
- have all reports modified → starting from the results tables, ending with Dashboard and the 'Reports' tab in a sidebar ('Issues', 'Overview', 'Site Structure', 'Scraping');
- make a necessary export in .XLSX or .CSV format.
Note: we do not delete the data from hidden columns, try turning off / on any parameter, and see for yourself ;)
And, traditionally, a few hacks for using new functionality:
- (I've promised to tell you about it earlier) In a new 'Site Structure' report you can see all selected parameters after regular columns with depth levels → disable / enable parameters, sync the table, and only those parameters that you need will be included in the exported report.
- Quickly switch between parameter sets in a sidebar after creating your custom templates or selecting default ones.
- Use the quick search by parameters → for example, if you only need a report on the Title tag, then click the 'Untick all parameters' button, enter 'Title' in the search, make the necessary tick and sync the table using the new function.
- Click on the parameter to quickly scroll to it in the current table → it saves time when you need to quickly analyze the parameter in a massive table.
9. 'Filter by Value' Option
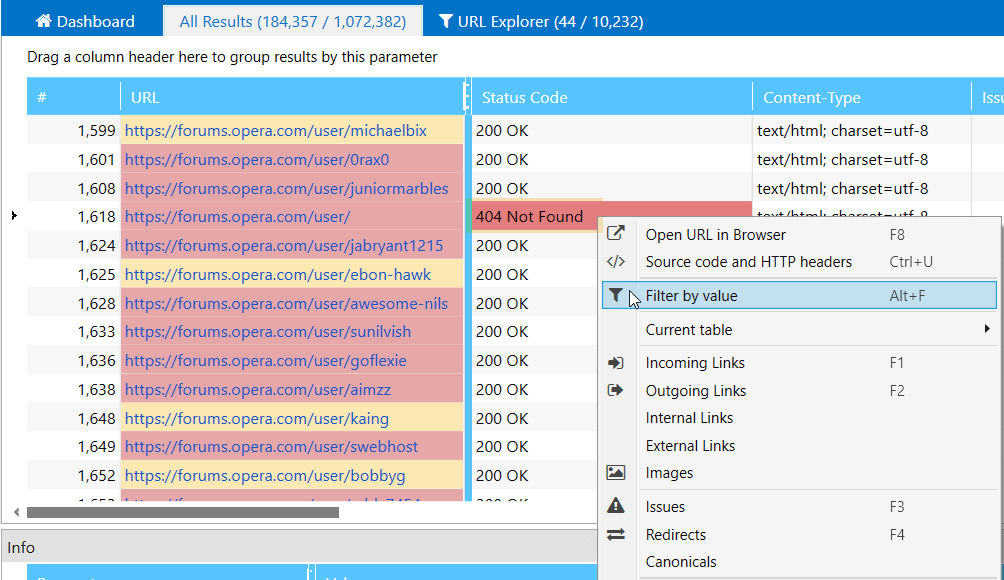
Similarly, this feature was moved from the Netpeak Checker 3.0 update. It allows you to quickly filter the results based on selected data in the cells. For example, looking through a table you've found out that some pages return a 404 error: select the corresponding cell in the 'Server response code' column and use the context menu to choose the 'Filter by value' option:
New feature is available:
- in the main table
- in all tables of the 'Database' module
- in the tables of the 'XML Sitemap validator' tool
Note that you can select several cells at the same time, but only within one row. If you like hot keys as much as I do, you can use Alt+F.
10. Other Changes
Although these changes are 'other', it can be useful to read more about them, as they often relate to usability and solve specific tasks or problems:
- We've removed links underlining in the program tables and exported reports. The thing is that with such highlighting, the spaces and underscores in the URLs are not visible (e.g., https://example.com/under_line).
- Tabs auto-switching has been changed: now, when crawling starts, the last opened tab in the 'Reports' block in a sidebar does not change. Previously, there was an automatic switch to the 'Issues' tab. It was quite inconvenient, for example, when working with scraping.
- Now the value of the 'Content Type' parameter is transformed to a lower case. Specifying 'Content Type' with a non-standard register is not an issue. And the 'Overview' report in a sidebar has become less loaded and more informative.
- A time stamp is added at the end of the export files name. When exporting the same report on the same day, identical file names were generated, and Excel cannot open two files with the same name (even if they are in different folders).
- The 'Recrawl URLs' option in the context menu was moved below to reduce the chance of accidentally calling it, because it is applied instantly without additional confirmation. However, its place was not vacant for long, now a new function 'Filter by value' is placed in there.
- Scraping summary: now if you press the 'Export' button in the internal scraping table, instead of exporting current table you'll see a list with export options (similar to the new report export menu): 'Current table results', a new 'Scraping summary in single file (XL)' report, and renamed old 'Data for scraping conditions in separate files (XL)' report.
- Scraping summary: if the page does not have data in any column, then the corresponding cells stay empty. Previously there was the '(NULL)' value.
- Scraping Overview: the 'Max results / scraping condition' default value as been changed from 1 to 5. It's convenient for those who use the same condition to scrape multiple items on a page.
- Scraping summary: we've added hints to column headers. It is useful if you use custom names for scraping (for example, 'Price'). In this case, when you hover over the header, you will see the scraping condition.
- The 'XML Sitemap validator' tool: the order of parameters when clicking on an issue in a sidebar has been redesigned. Now you'll firstly see those parameters that contain the selected issues, and then all others (the logic is similar to the 'Issues' report in the main table).
- The 'Internal PageRank calculation' tool: export button has been moved and it is now designed in the style of a scraping overview.
- The 'Internal PageRank calculation' tool: we've added the ability to export the 'PageRank amount changes' table. This table was very depressed due to lack of attention, but we've fixed it :)
- If you hover over the functions in the 'Parameters' tab in a sidebar, you'll see that now they are displayed with buttons, icons, and hints: 'Untick all parameters', 'Collapse all', 'Sync table with selected parameters', 'Scroll to selected parameter in current table'.
- The hosts sorting in the 'Site structure' and 'Overview' reports has been reworked. Now sorting initially occurs by the number of points (the fewer there are in the host, the higher it is), and only then by alphabet. Subsequent segments in the URL are always sorted alphabetically.
- The explanatory texts and links are now always active in the crawling settings in the 'Virtual robots.txt', 'Scraping', and 'Authentication' tabs regardless of the checkmark.
- We've removed the 'Delete all results' option from the 'Project' menu because it is outdated. If you need to recrawl the results, use the 'Restart' button, and to start a new crawling, select one of the options from the same 'Project' menu: 'New' (project) or 'New window'.
- The font of all numerical values has been changed on the status panel and in the loading windows so that they would 'twitch' less (in fact, we gave them a little Xanax, but not a word about this to anyone).
- In order to explain some nuances better, we've changed texts within the program. In future releases, we plan to work more with the texts, so if you notice any inaccuracies, drop a line to our support team.
- We've fixed a lot of issues in the program related to the crawling and usability.
11. In a Nutshell
So to sum up, in Netpeak Spider 3.1 our team has:
- Reworked the report selection menu and added 4 new reports: 'Site structure', 'Redirects: incoming links and final URLs', 'Scraping summary in single file (XL)', and 'Pending URLs';
- Implemented tables customization opportunity (width, columns position, and so on) with auto-saving;
- Added expected crawling duration in the status panel;
- Added the functions 'Sync the table with selected parameters' (in a sidebar in the 'Parameters' tab) and 'Filter by value' (in the context menu of most tables);
- Made more than 20 improvements in the interface and usability.
Colleagues, thank you for your attention :) I hope that now your work with Netpeak Spider will become even more effective! Leave a comment with a review or suggestion, while we are working on one of the most requested features within Netpeak Spider 3.2 ;)
Digging This Update? Let's Discuss Netpeak Spider Perks in Person

Was this article helpful?
That’s Great!
Thank you for your feedback
Sorry! We couldn't be helpful
Thank you for your feedback
Feedback sent
We appreciate your effort and will try to fix the article